
语言模型经典论文阅读:Word2Vec, GloVe, FastText
Word2Vec
原论文:Efficient estimation of word representations in vector space
作者:Mikolov Tomas, Chen Kai, Corrado Greg, Dean Jeffrey
发布时间:2013年
GloVe
原论文:GloVe: Global Vectors for Word Representation
作者:Jeffrey Pennington, Richard Socher, Christopher D. Manning
发布时间:2014年
FastText
原论文:Bag of Tricks for Efficient Text Classification
作者:Armand Joulin, Edouard Grave, Piotr Bojanowski, Tomas Mikolov
发布时间:2016年
本文内容参考:
# 序言
在学习了上一篇文章 (opens new window)所提到的 Neural Probabilistic Language Model(NNLM) 之后,我们能够认识到引用神经网络设计语言模型,同时将自然语言中的 words 转换为词向量能够十分有效地表示 words 这一级别的文本单位。在沿袭这样的思路之后,学术界又提出了新的语言模型,其中我最近学习了 Word2Vec, GloVe 及 FastText 。虽然在很多场景中它们的表示效果并不能与预训练语言模型的结果相比,但它们背后的研究思路能够帮助我们如何更好地 “站在巨人的肩膀上”。
# Word2Vec
在提出 Word2Vec 之前,该模型的作者们已从 NNLM 中受到启发。Word2Vec 的核心思想就是通过 back propagation 来训练出能够将原本表示为 one-hot 形式的 words 转换为维度小的分布式表示形式(distributed representation) 的神经网络模型,而这个模型的权重(weight, 往往是一个矩阵) 就是能够将某个 word 的 one-hot 向量转换成分布式表示向量的关键产物。
不同于 NNLM 在使用上下文(context, 即当前关注的 word 前、后另外的 words) 的方法,Word2Vec 考虑到了一个现实中更一般的情况,即一个 word 在句子中的出现是与其周围一定范围内的 words 相关。因此 Word2Vec 在实现方式上也能够细分为两种类型:
- Continuous Bag of Words(CBOW) Model
- Skip-Gram Model
这两种类型的 Word2Vec 模型结构分别如下:

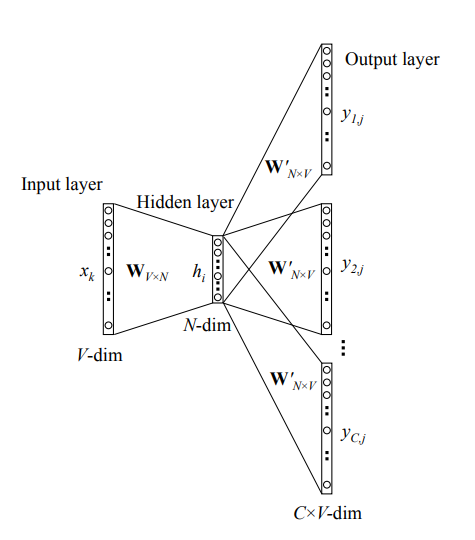
Word2Vec Skip-Gram 模型,其特点为以当前的 word 作为输入,预测其周围一定范围的 context 的 one-hot vectors
我们可以注意到,无论是哪种实现方式,模型隐藏层(hidden layer)和输出层(output layer)都只做线性变化;另外,模型最终输出的还是 |V| 维的向量(与输入的 one-hot vector 维度相同,V 为词典大小),这意味着 Word2Vec 所关注的并不是输出的向量,而是试图通过共享隐藏层权重矩阵并按照 back propagation 优化,使得最终能够通过该权重矩阵将所输入的 word 对应的 one-hot vector 转换成能较好地表示该 word 的低维向量。
因为语料数据往往包含了成千上万个 word,而 Word2Vec 模型的输入输出均为 |V| 维向量,这使得训练模型会造成很大的开销,针对这点,Mikolov 等人还提出了两种优化方式:
- Hierarchical Softmax
- Negative Sampling
值得一提的是,将 words 转换为低维的分布式表示之后,word 与 word 之间的差异可以理解为在一个向量空间的线性距离(这个线性空间的维度即为分布式表示的向量维度)。按照这样的逻辑,我们可以认为语义相似的 words 之间的距离应该较小,而语义差异较大的 words 之间的距离应该较大(举个例子,"lion" 这一个 word 与 "tiger"、"cat" 等表示动物的 words 距离相近,而与 "flower"、"tree" 等表示植物的 words 距离较远)。相比于 one-hot 的形式下 words 之间的距离是相等的,Word2Vec 使得计算机能够理解文本所蕴含的语义信息了。
# GloVe
GloVe 模型的全称为:Global Vectors for Word Representation,与 Word2Vec 相似的是目的也是将 words 转换为低维的分布式表示向量。但又正如其名称中的 "Global",GloVe 希望改进 Word2Vec 模型只用到了局部 context 信息的缺陷(在这篇文章中,作者将其归为 Local Context Window Methods),并将语料库中的全局的统计信息(Statistical Information)运用到构建语言模型之中。
基于这样的想法,Pennington 等人提出了将语料库中所有句子的 word-word cooccurrence 信息运用到语言模型的构建中,并以词汇 "ice" 和 "steam" 为例解释其中的原理:当我们想表示这两个 words 时,我们可以借助“中间词”("solid" 和 "gas"),探究这两个 words 与所选取的“中间词”的关系;一般情况下,语料数据中与 "ice" 共同出现的应该是 "solid" 居多,而 "steam" 与 "gas" 共同出现居多(因为冰是固体的,蒸汽是气体的),因此在整个语料库中 值更高而 值较低,而它们的比值 分别会是一个较大、小的数。
有了这样的理论依据后,GloVe 采用了记录语料数据中的共现矩阵的方式帮助语料模型的建立。根据 Pennington 等人的思路,在建立 GloVe 模型前应先定义一个窗口值 来确定当前 word 的 context 选取范围,并在这个范围中记录共现信息;由于窗口值可能大于 1,所以 Pennington 等人提出根据 context word 与当前 word 的距离为共现情况赋权重,使得与当前 word 越接近的 context word 所提供的共现信息越多,一般为 。 设 word 与 之间的关系与 word \widetilde{w_k} 有关,那么可以拟合出以下关系:
经过若干次的推导之后,可以在这个等式的基础上得到 GloVe 模型独特的损失函数:
整个推导过程搬运自 知乎专栏-“简介GloVe词向量:推导、实现、应用” (opens new window),如下:

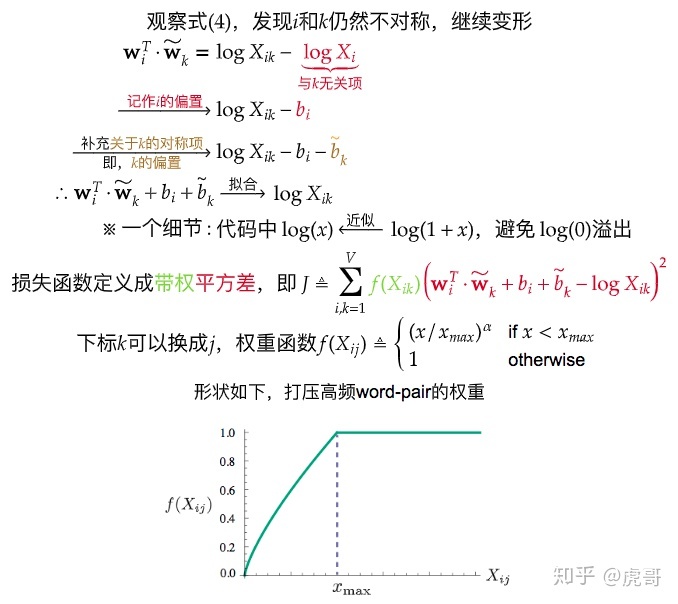
而经过 Pennington 等人的多次实验,发现函数 中的 分别设为 100 和 0.75 时效果最好。
# 实验
根据上述理论知识,我在之后实现 GloVe 模型的实验中使用了 sklearn 中的数据集 20newsgroups 中的 1000 篇新闻作为语料训练模型,最终通过 matplotlib 可视化的方式展现词典中的 300 个 words 的分布情况如下图:
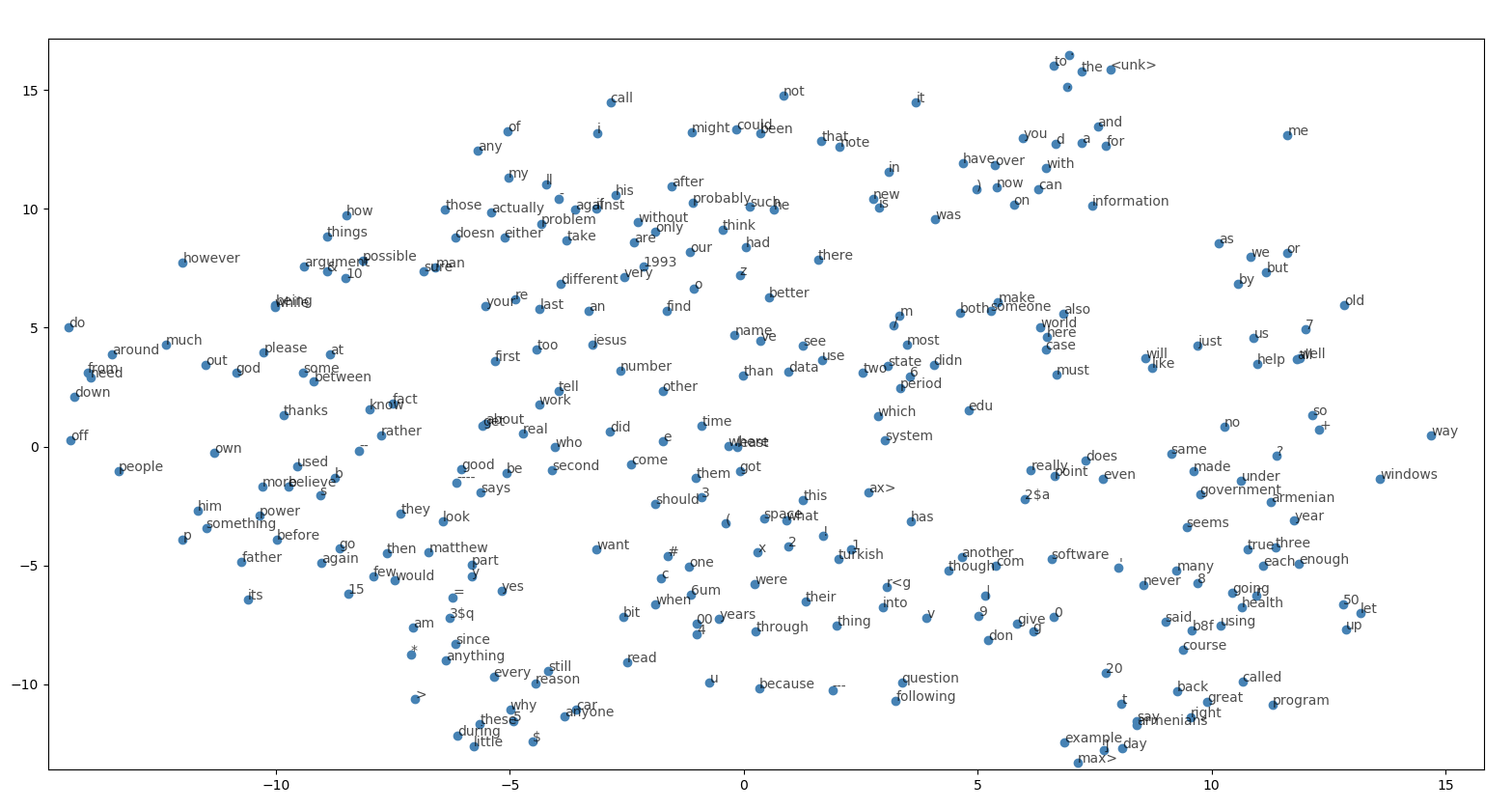
可以观察到 "following" 和 "question" 这样能够组成有意义的表达 "following question" 的 words 之间的距离较小,同时 "every" 和 "anything" 这样的词义相近的 words 之间的距离也较小,但整体的分布情况仍不尽人意,除去 GloVe 模型仍有改进空间不谈,这主要与实验所用的语料规模小有关系
# FastText
与 Word2Vec 和 GloVe 有差异的是,FastText 主要用于文本分类任务;它的核心思路是将句子中的各个 word 转换为特征向量后,通过求这些 word vectors 的平均值向量作为句子的 representation 再经过线性变换输入到隐藏层,最后在输出层输出对应的分类类别向量。FastText 的模型结构如下图:
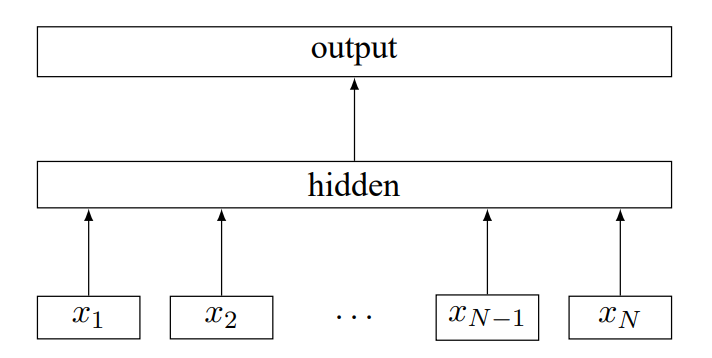
整个模型结构仅由 hidden layer 与 output layer 组成,而 {x1, x2, ... , xN} 为句子中各 word 的特征向量
FastText 在获取各 word 的特征向量时,不仅使用了它们的分布式表示向量,还引入了 n-gram feature;与传统意义的 "n-gram" 不同,FastText 引入的 n-gram feature 是基于 character level 而不是 word level 的(比如设 n 为 3 时,词 "right" 对应的 3-gram feature 为 "rig", "igh", "ght" 的特征向量)。
当然,FastText 的另一个特点是 fast,那么它在训练、推理时能做到 fast 的原因不仅是因为模型参数量少,还因为使用了 Hierarchical Softmax,它相比于使用 softmax 计算分类情况的时间复杂度 能取得更小的时间开销,将时间复杂度降为 (假设为 k-分类任务)。
# 实验
为测试 FastText 模型在速度快的情况下所取得的分类效果,我选取了 AGNewsDataset 作为训练、验证和测试集。在设定 word embedding 的维度为 200,隐藏层 unit 数目为 100 ,同时设置学习率为 1e-3 并训练 10 个 epochs,最终能获得如下表的分类结果:
| f1-score | support | |
|---|---|---|
| World | 0.91 | 1900 |
| Sports | 0.95 | 1900 |
| Sci/Tech | 0.87 | 1900 |
| Business | 0.87 | 900 |
| weighted avg | 0.90 | 7600 |
注:本文实现的 FastText 并没有采用 Hierarchical Softmax(仅使用普通的 softmax 做多分类)和没有引入 n-gram 特征,但实际上在同个数据集上所达成的分类效果比单层 RNN 的分类效果好(推测与文本长度选定有关)
# 总结
通过将 words 转换为维度较低且能够包含语义信息的分布式表示,各种下游的 NLP 任务得以更好地实现;Word2Vec、GloVe、FastText 这三种模型为此后的语言模型同样提供了宝贵的思路,同时这类“静态”语言模型的缺漏也在此之后得到了补充(因为基于局部 context 的语言模型并不能较好地解决一词多义等复杂的情况)。路漫漫其修远兮,吾将上下而求索。语言模型的广阔天地仍待我们探索。