
语言模型经典论文阅读:A Neural Probabilistic Language Model
原论文: A Neural Probabilistic Language Model
作者: Yoshua Bengio, Réjean Ducharme, Pascal Vincent, Christian Jauvin
发布时间:2003年
本文内容参考:
# 序言
随着预训练语言模型(Pre-trained Language Model)席卷自然语言处理(NLP)各项任务,对于某个 NLP 任务的研究,我们常常会首先考虑能否使用预训练语言模型进行优化,而本文希望在站在巨人肩膀之前,“观望”巨人是什么样的。本文就 2003 年所提出的 Neural Probabilistic Language Model(NNLM) ,记录作者的学习记录,希望能够通过了解这个发布至今快 20 年的语言模型来帮助接下来的学习。
# n-grams 模型
在解答为什么要提出 NNLM 前,我们必须了解在 NNLM 提出前,在研究人员中使用广泛的语言模型: n-grams 模型。 n-grams 模型是一种基于统计的语言模型,它的核心思想可以理解为计算概率论中的条件概率。 我们可以将一个自然语言句子看作是由 m 个词组成的有序序列 s,则在语料库中生成(或者说出现)该句子的概率记为:
由于上式在计算上的难度较大(特别是句子长度大时),因此减少计算难度的一个方法是引用马尔科夫链的假设,即理解为某个词在句子的某个位置出现的概率只与前 n-1 个词有关系,用式子表示为:
而这里的 n 也是 n-grams 模型中的 n;其中,n 设置为 1, 2, 3 都是较为常见的,它们对应的 n-grams 模型是 unigram, bigram, trigram;我们以 bigram 为例,计算一个短句 "I want to eat Chinese food" 的概率:设句子为 s,则
为了计算 ,我们就要根据语料库统计等号右边的概率数值,这就要求我们先得到下面这样一个出现频数矩阵:
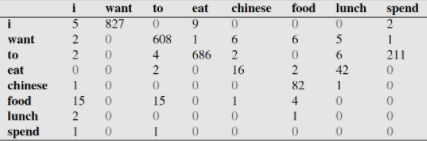
以第一行第二列为例,数值 827 代表在语料库中,'i' 之后为 'want' 的组合出现了 827 次;这个出现频数矩阵是计算概率矩阵的前提。图片来源:自然语言处理中N-Gram模型介绍 (opens new window)
根据出现频数矩阵和在语料库中 "i" 出现了 2533 次的信息,我们可以计算 ,以此类推可以计算出下面这个概率矩阵:
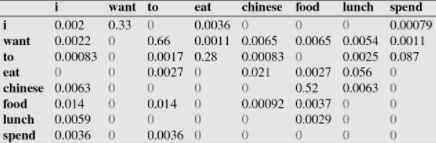
查阅上述概率矩阵,我们就可以计算出 的概率数值了;看起来计算这样一个矩阵不是很费力气,但随着 n 的取值变大,设语料库的词语数量为 T,需要计算的参数量 也会越来越大,这就是论文作者所提到的 “维度诅咒”(curse of dimensionality)。
# 为什么要提出 NNLM?
基于 n-grams 模型,虽然研究人员们提出了很多改进方案,比如 back-off trigram models,但除了上节提到的 "curse of dimensionality"外,论文作者针对 n-grams 只运用了文本序列中的词频、词序信息的缺点,认为文本序列中仍有除了上述两个特征外的有用信息,比如语法、句法方面的信息;以句子 "The cat is walking in the bedroom" 和 "A dog was running in a room",这两个句子的词语组成结构是相似的,且 "dog" 和 "cat" 在各自从属的句子中所担任的语法角色是相同的,那么语言模型应该运用这些信息。 因此,论文作者提出了使用 多层感知机(MLP) 构建语言模型,试图解决 n-grams 模型出现的问题。这样的想法在当时是十分新颖的,而它也为后续的 word2vec 模型提供了思路。
# NNLM 模型
模型结构分为三层,分别是输入层(映射层)、隐藏层和输出层,如下图所示:
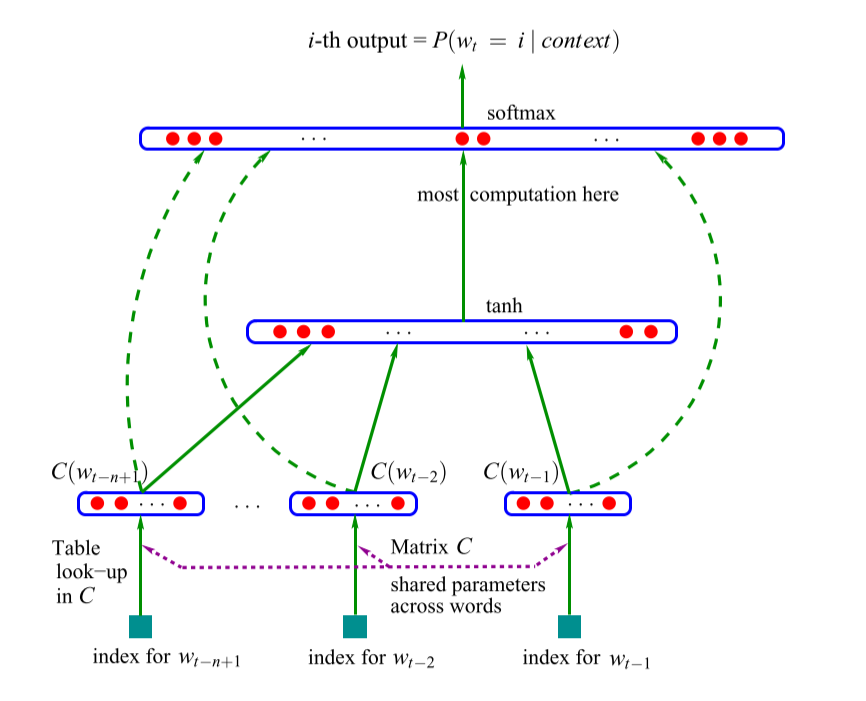
我们先从输入层看起,论文作者提出使用一个矩阵 C 来表示输入的词语(words);然而,这样的矩阵便是 word embedding,这样的设计使得每个词语可以使用一个维度较低的向量表示;经过 word embedding 后,我们可以得到一个由前 n-1 个词组成的矩阵 X,即:
之后,矩阵 X 在隐藏层中与权重矩阵 H 进行矩阵相乘,之后与隐藏层的 bias 向量相加,最后通过 tanh 函数激活后输入到输出层;隐藏层的输出为:
矩阵 X 除了需要输入到隐藏层之外,还需要输入到输出层,设输入层到输出层的权重矩阵为 W,隐藏层到输出层的权重矩阵为 U,bias 向量为 b,则输出层的输出为:
最后,通过 softmax 函数,可以在 矩阵中求出最有可能出现在当前句子位置的词语为语料库中的哪个 word。
# Word Embedding
虽然 NNLM 的本质目的是在给出前 n-1 个词语的前提下,预测当前词语最有可能的情况;但其副产物 Word Embedding 却有着重要意义,即上一节中提到的矩阵 ;正是因为 Word Embedding,词语文本能够映射于一个低维的向量,这使得词语能够较好地表示出来并为后来 Word2Vec 模型提供了思路。
# 实验
论文的实验分别在 the Brown Corpus 和 the Associated Press News 两个语料库中进行;而实验的评估指标为 Perplexity 值,这个指标应为大于零的正整数,而数值越小说明语言模型效果越好;下表为论文在 the Brown Corpus 中的实验结果,其中训练集、验证集、测试集数据规模分别为语料库中 800000, 200000, 181041 个 words。
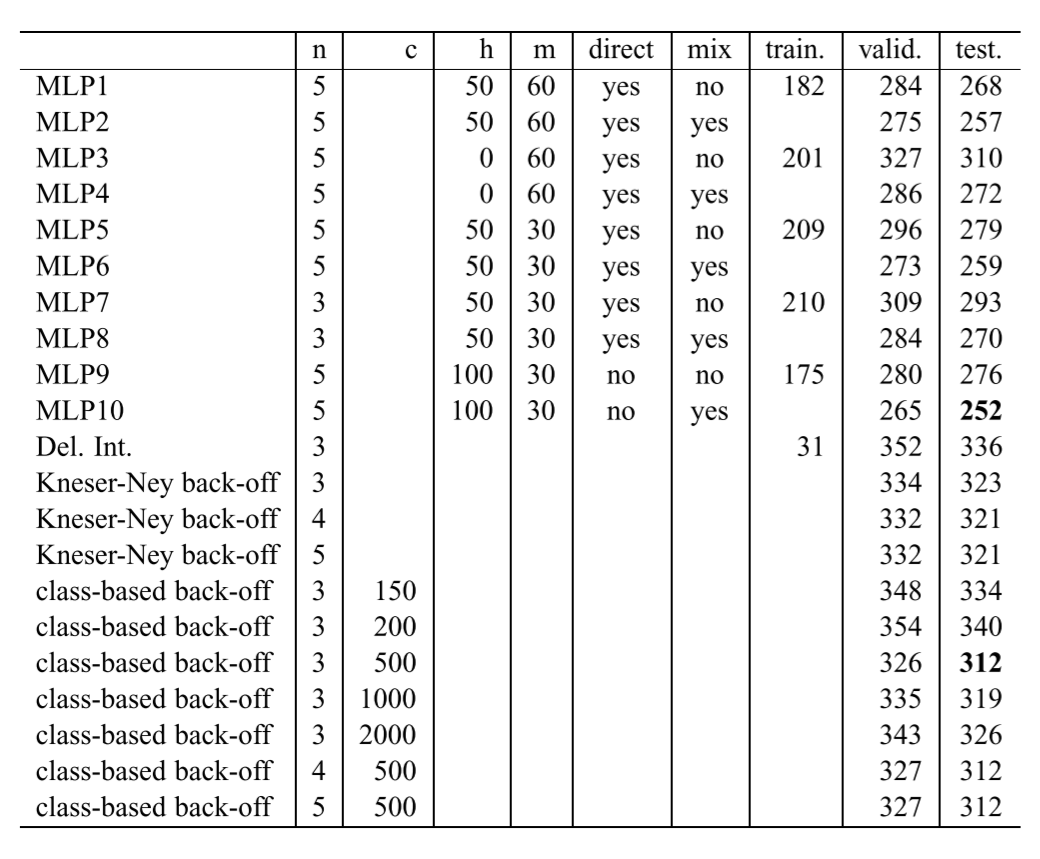
由实验结果可见,当超参数设置为与 MLP10 相同时,模型的效果是最好的;其中 n 指的是令模型根据前 n 个 words 预测下一个 word; h 指的是隐藏层单元数目;m 指的是所设置的词向量的维度大小; direct 为输入层的输出是否直接传输至输出层; mix 为 NNLM 是否与 n-grams 模型混合
本文同样以 the Brown Corpus 作为语料库,通过引入 nltk 库中的 nltk.corpus.brown 去重后的所有 words 作为数据,同时将词频小于等于3 的 rare words 全部替换为特殊符号 "[rare]" ,超参数分为设置为 ,其余超参数设置与论文相同以复现本实验。实验结果 Perplexity 值为 607。
# 结论
虽然 NNLM 对比现有的语言模型,其预测效果并不优秀;但我们必须认识到这个模型发表于 2003 年,并为日后的成熟语言模型提供了重要的参考思路,其副产品 Word Embedding 更是文本表示(text representation) 中的佳话。