
Reading Note:A Semantic and Syntactic Enhanced Neural Model for Financial Sentiment Analysis
# Reading Note:
From: Information Processing and Management (Journal)
URL: https://www.researchgate.net/publication/360502398
Authors: Xiang Chunli, Junchi Zhang and Fei Li.
During these years, numerous reseachers has focused on the finance-specific NLP tasks including Stock Prediction and Financial Sentiment Analysis (FSA). As one of the branches of Sentiment Analysis, FSA aims to predict the sentiment intensity(a real value) for a specific target(company or stock symbol) in a text review. The difficult problems of the task are distinguishing different descriptions for different targets and predicting the values of the sentiment intensity exactly. To slove such difficulties, this paper proposes a semantic and syntactic enhanced model named SSENM, which can utilize the dependecy relation and context words to facilitate the prediction of sentiment intensity. The results of the experiments in two benchmark datasets, SemEval2017task5 and FiQA challenges, shows the excellent performance of SSENM and it overperforms the SOTA model by 2% wcs scores on SemEval2017task5 and 3% R2 scores on FiQA.
# Motivation
Following the concise introduction written above, an ideal model should be able to understand the financial entities and know the semantic interactions to the context words. Furthermore, the specific domain knowledge is required to annotate the target terms and corresponding sentiment intensity in FSA dataset. To the above mentioned benchmark datasets, they only contain one thousand intances respectively. The sparsity of labelled data affects the performance of models and easily causes the overfitting problem. Previous non-neural models are mostly based on the hand-craft features, which are labor-intensive and cost much. However, even the semantic and syntactic information can be encoded by neural representation and the attention mechanism improves the performance of neural models, Xiang et al. summarize two shortcomings of previous neural models:
- They do not assign larger attention scores to relevant words for the targets and reduce the attention weights to irrelevant, noisy information.
- Explicit syntactic information is not used to facilitate the process of modeling the relation between targets and relevant contexts.
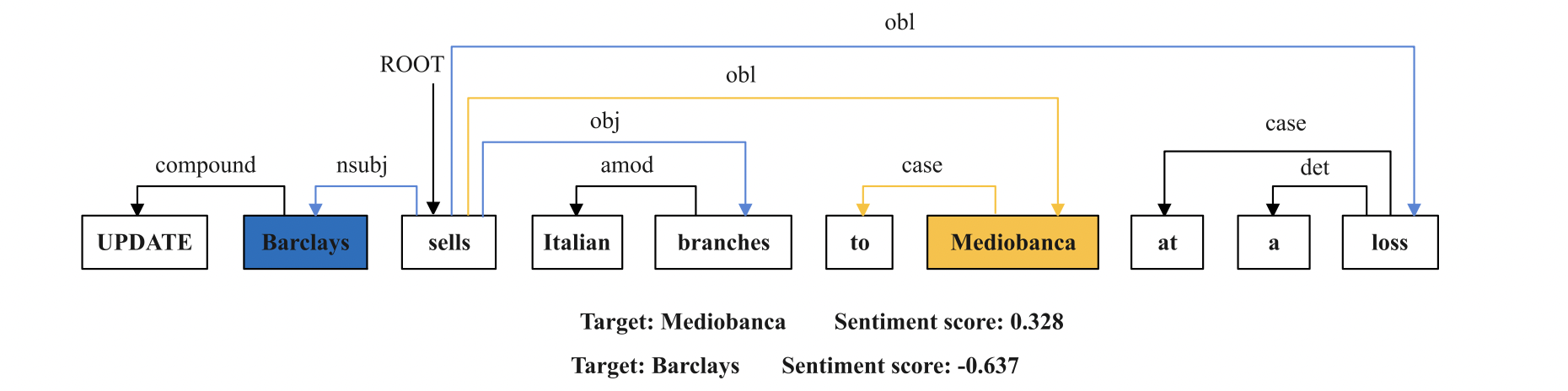
Thus, SSENM is designed to utilize more semantic and syntactic information to finish the FSA task. And its main idea is illustrated in Figure. 1 .
# Approach
In this section, the overall architecture of the model is introduced firstly and then the details of each component are illustrated. As shown in Figure. 2 , before outputing the sentiment scores, the model processes the input data through many steps including tokenization, embedding, features extraction.
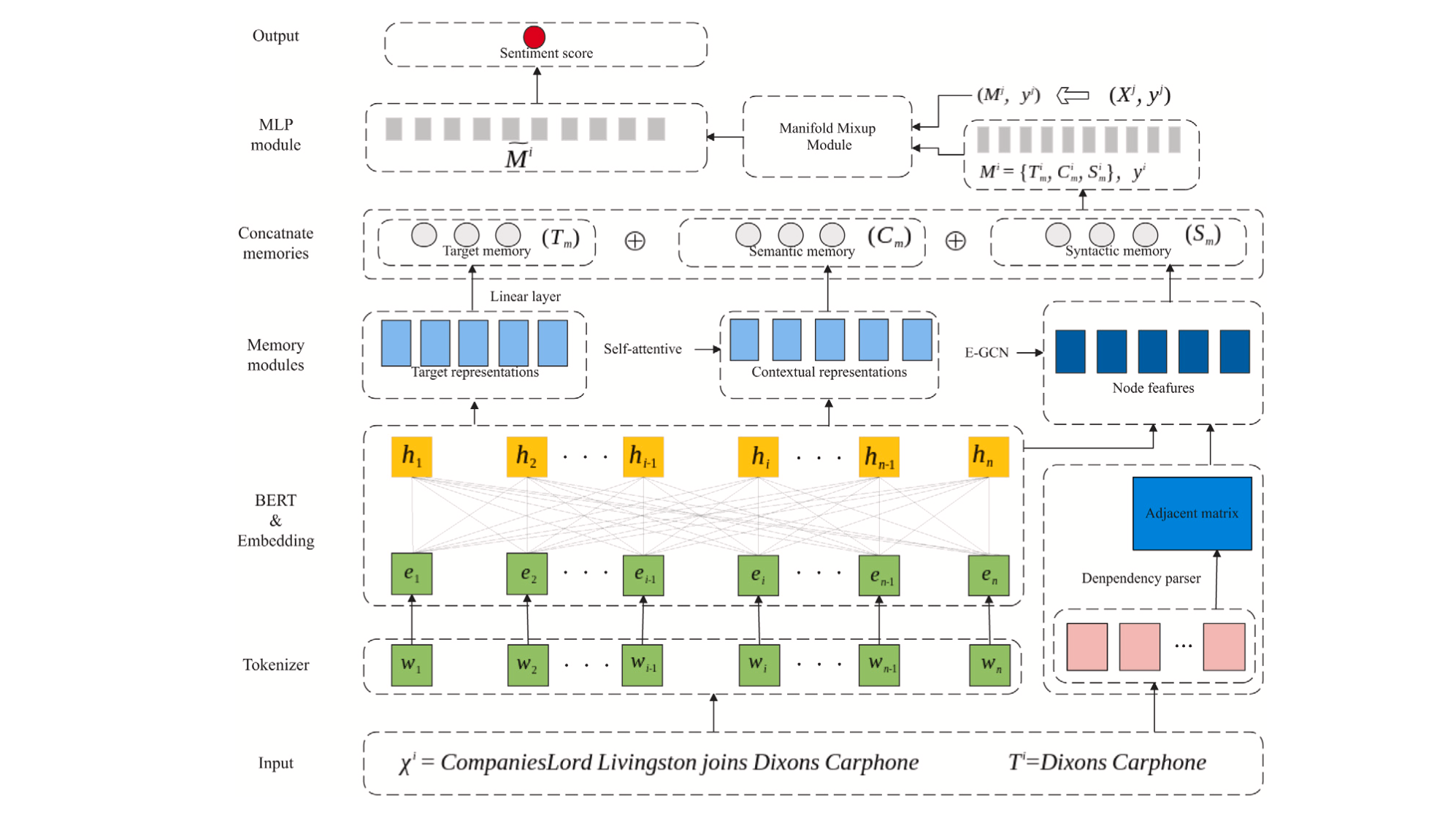
# Embedding Layer
At the beginning, the input instance is set to a special sequence: [CLS] + sentence( ) + [SEP] + target( ). The SSENM model uses the vanilla BERT model and its tokenizer to tokenize the input intance and get the input representaion. Following the strategy of BERT that uses sub-words as input instead of words, a specific word might be broke down to the form of its prefix, root and suffix. For example, the word "going" will be divided to "go" and "##ing" after tokenization. The embeddings of each corresponding word are average-pooled in the last layer of BERT, and the output sequence(hidden state) is denoted as .
# Feature Extraction
Except the basic proceeding of feature extraction, this paper attempts to process the representations respectively and constructs the target memory, semantic memory and syntactic memory. After that, the SSENM model concatenates these memories and sents it to the Manifold Mixup Module as the final representation of the input data. Three Memory Modules are introduced as follows:
# Target Memory
Differing from choosing the first token [CLS] as the sentence representation, this paper proposes a target-aware strategy to construct the target representation and the contextual representation in sparsity. It denotes the first and the end token index of the target as and . The target memory is constructed by the output sequence of BERT and a linear layer:
Where is a 0-1 matrix with the same dimension to , and all elements in row are 1 if ; the target memory is denoted as .
# Semantic Memory
The attention mechanism shows its excellent ablility in focusing on a special set of related words in the sentence, and SSENM utilizes it too. But before utilizing the attention mechanism, SSENM should mask the token [PAD] and other irrelevant target terms as they have no contribution to capture the semantic feature about the current target term. To implement such goal, Xiang et al. constructs a Mask vector and each its element( ) is:
In this equation, is the index set of other targets mentioned and the token [PAD]. The attention mechanism takes the entire hidden state and the Mask vector as input so it can output the attention weights :
Here, and are learnable parameters and their dimensions are set as 100 in this paper; represents the semantic memory.
# Syntactic Memory
Despite utilizing the attention mechanism to facilitate the process of feature extraction, this paper considers that some inevitable errors will incur, for example the attention mechanism may wrongly highlight the error relation between the target and irrelevant sentiment terms. Recent work has shown the Pre-trained Language Models(e.g. BERT, RoBERTa) can encode implicit linguistic knowledge but they do not properly isolate syntax when evaluated as syntactic probes (Maudslay et. al, 2021). Thus, this paper proposes to explicitly introduce the syntactic information such as dependency relations as complement. For this purpose, the Graph Convolution Network (GCN) is used to encode the dependency relations between the words. Before using the GCN model, the graph structure must be constructed to represent the dependency relations of the input sentence. Specifically, we can construct the dependency graph by the dependency parsers toolkit. And to represent the dependency graph, the adjacent matrix can be built to record all the dependency relations in the dependency graph. We denote the input sentence as and the tokens sequence of can be denoted as , where is the last token of the sentence after tokenization by the tokenizer of the dependency parser. The adjacent matrix () is formalized as:
Following the design of this paper, even the dependency graph is not the self-loop graph, each word intuitively has a strong relationship with itself. According the generic GCN model, all dependency relations are treated equally and they are reprensented as the real value 1 in the adjacent matrix . However, this paper considers that the importance of different dependency relations should not be same. So the E-GCN model is constructed to model the contextual features by weighting each word-to-word dependency relations and recording them in the weighted adjacent matrix . Because of the difference between the results of tokenization from BERT and the dependency parser, the SSENM model must implement the alignment of tokens before the covolution operation. For example, the word "going" has been tokenized by the BERT tokenizer as {go, ##ing}, but it is not tokenized as two sub-words by the tokenizer of the dependency parser. So we choose the hidden state of "go" to represent the feature of "going". After the alignment, the elements of the weighted adjacent matrix is formalized by:
In this equation, and are the hidden states of the i-th and j-th words, is the length of the input sentence. By the E-GCN, the each node of the dependency graph can get the information of left neighbor node, right neighbor or itself. So the final feature of is :
After computing all the of the input sentence, the syntactic memory of the sentence is the sum of all , which is denoted as .
# Data Augmentation and Prediction
A Multi-Layers Perception(MLP) are set to get the fusion of target memory, semantic memory and syntactic memory. The input of the MLP is the concatenation of these memories and it is denoted as . Before the fusion and prediction, a data augmentation strategy named Manifold Mixup is utilized to create the pseudo training instances.
# Manifold Mixup
Although the Manifold Mixup strategy was initally introduced in Computer Vision, this paper proposes an adaptive alternative for sentiment analysis. The detail of algorithm is illustrated as Figure. 3.
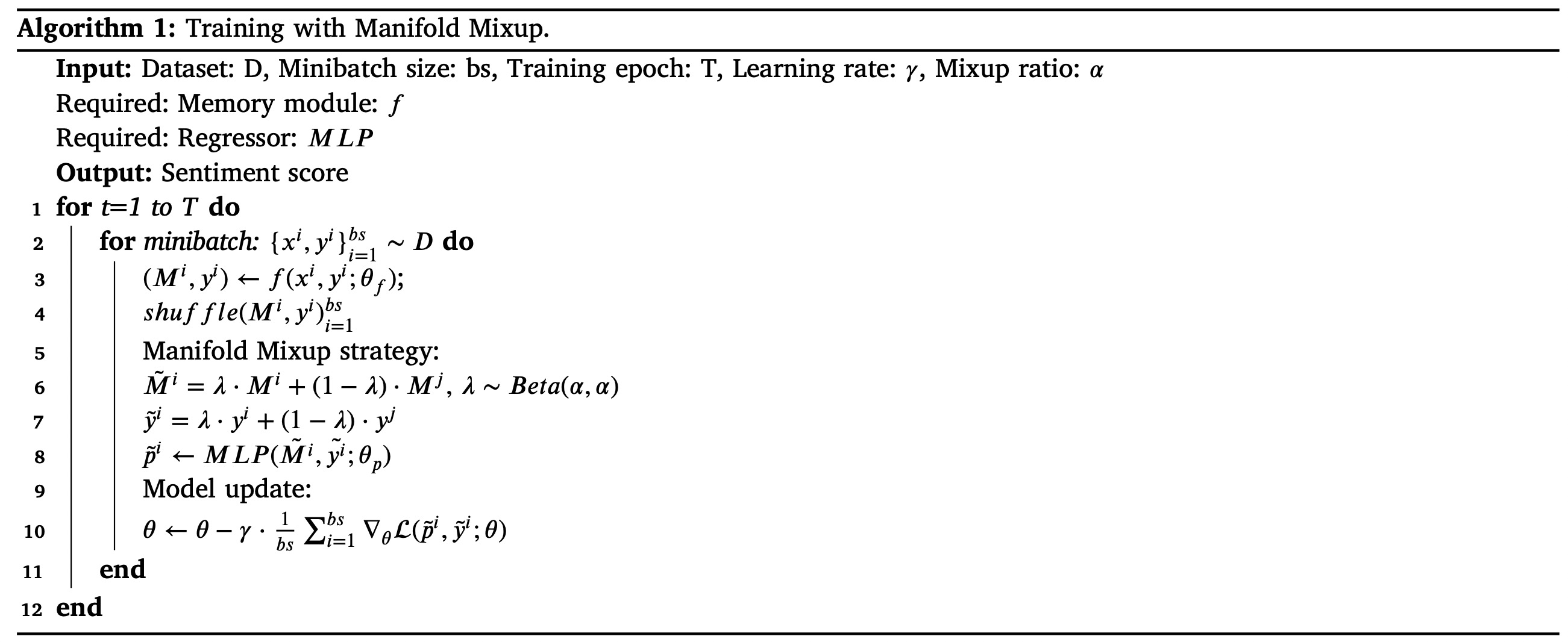
where the , and are the parameters of the memory module, the MLP module and the final model, respectively. The pseudo training instances are constructed as follow:
Here, is the mixup ratio sampled from a Beta distribution and is the hyper-parameter to control the intensity of interpolation between feature-label pairs.
# Output Layer
Finally, for each input instance enhanced by the Manifold Mixup , the output of the MLP is the corresponding sentiment score, and it is computed as:
In these equations, denotes the sentiment score of the training instance , and the value of is in .
# Experiment
In this section, we introduce the used datasets and the results of the experiment.
# Dataset
Two publicly available datasets named SemEval2017task5 and FiQA are chosen for the experiment. To reduce the noise, the urls and usernames existing in the text are replaced with the tokens "<url>" and "<username>". For the setences without explicit target terms (but marked as the annotation), Xiang et al. adds the corresponding target term at their beginning.
# Results
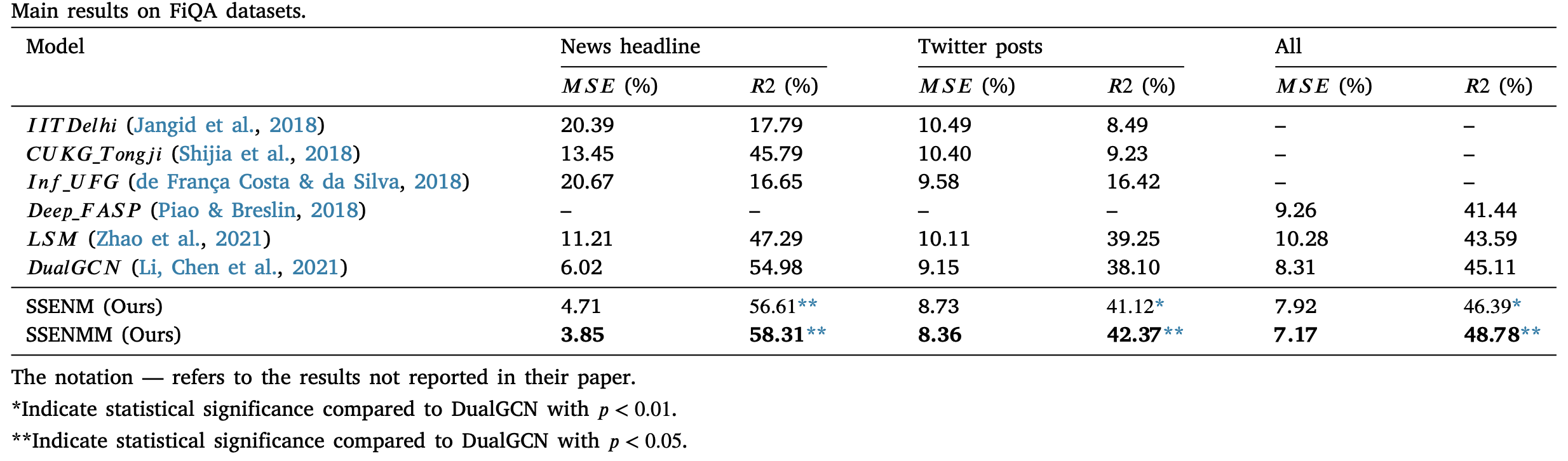
The results on SemEval2017task5 test datasets and FiQA datasets are illustrated on Table. 1 and Table. 2. Different evaluation metrics are used in the experiment based on different datasets respectivly. For SemEval2017task5, this paper utilizes the weighted consine similarity (WCS) to measure the proximity degree between the predicted and true labels. For FiQA, the Mean Square Error (MSE) and the R squared (R2) are used to measure the error rates and fitting ability of models. Unlike the WCS and R2, the lower value of WCS represents the better performance of the model.

# Analysis
In this section, we show the results of the ablation studies and the comparsion between generic GCN and E-GCN.
# Ablation Studies
This paper attempts to test the effect of each componment of the proposed model on SemEval2017task5 test datasets and the result is shown on Table. 3.

Following Table. 3, the reduction of Manifold Mixup and E-GCN componments are more sensitive.
# Comparsion of GCNs
One of the most novel strategies proposed by this paper is changing the GCN model used at the step of getting the syntactic memory. Table. 4 shows the performances of the model based on generic GCN and proposed E-GCN. Obvious improvements prove the importance of measuring the weights of different dependency relations. Figure. 4 shows the D-based and WD-based adjacent matrixes of a specific sentence.

