
Reading Note:Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis
From: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics
URL: https://aclanthology.org/2022.acl-long.152/
Authors: Yan Ling, Jianfei Yu, and Rui Xia.
It has been a while since writing last reading note, and today I would like to share a essay from ACL which is based on Multimodal Aspect-based Sentiment Analysis. To be honest, I have never heard about this theme, so I felt fresh when I searching for this essay. As what the title showes, it seeks to find a way to optimize the model for fine-grained multimodal sentiment analysis. The key of researches based on multimodal sentiment analysis is handling the fusion of different modals well, such as vision, speech and text. In this paper, Ling et al. start from the vision and language(text) modals and try to finish the task by seq2seq model. Before analysing the detail of the proposed approach, let me summarize two important pieces of information from this essay:
- It foucus on two sub-tasks of Aspect-based Sentiment Analysis(Aspect Terms Extraction and Aspect-based Sentiment Classification) simultaneously, and proposes a joint model for them.
- The proposed approach is based on pre-training language model, which can jointly handle the information from vision and language modals. Because of such strategy, the model can solve the problem that ignoring the multimodal alignment.
# Task Definition

Here is an example of the MABSA task including an image and a sequence of text. The goal of the task is trying to find one or more tuples consisting of aspect and sentiment polarity from the image and text. Usually, the text modal will provide most information about the task, however something different may exist in the text: In order to express disgruntlement, someone may write the irony and combine with an blue image. Thus, the information from vision modal can help to analyse the text exactly. For this example, UCL isn't the main aspect term of the text and few information about it is mentioned in the image, so the sentiment polarity of UCL should be neutral.
# Motivation
For the MABSA task, the prevalent models can be classified for two types:
- Models that are pre-trained on different modals respectively. The pre-training tasks of them are usually text-image matching and masked language modeling. The disadvantage of these models is ignoring the alignment of different modal.
- Models that are pre-trained on different modals simultaneously, but they aren't task-specific. That means they are lack of the abilities in extracting the aspect and opinion terms and aligning the information from different modals.
Because of the disadvantages of those models, Ling et al. propose their approach which based on a seq2seq model. Let's analyse its detail in next section.
# Approach
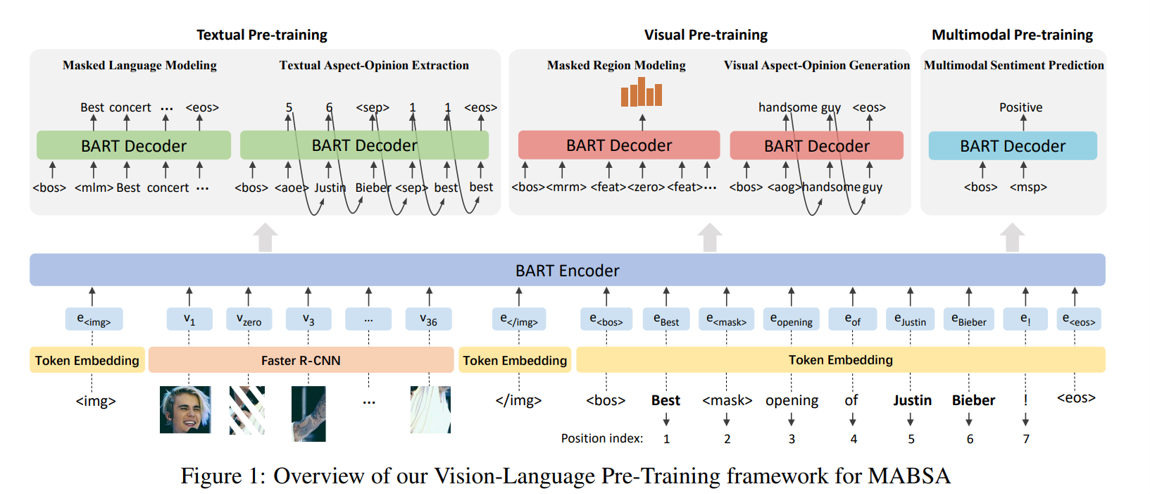
Figure. 1 is the overall architecture of the proposed model named Vision-Language Pre-Training framework. As its name shows, the approach is based on pre-training and it provides three types: Textual Pre-training, Visual Pre-training and Multimodal Pre-training. The model is pre-trained by MVSA-Multi dataset, which is a prevalent coarse-grained dataset consisting of tweets(each tweet consists of text and correspond images) from twitter (opens new window). In order to get the opinion and aspect terms from each tweet, Ling et al. utilized the Senti-WordNet (opens new window) to capture the words and phrases from text. If the words and phrases are included in the Senti-WordNet, they will be chosen as opinion terms. Likewise, the aspect terms also need to be captured by another tool: Named Entity Recognition(NER). By using NER for twitter, the specific words will be recognized as aspect terms.
# Feature Extraction

In this section, we talk about the method how Ling et al. choose to extract the features from images and text. First, for images, the model is based on Faster R-CNN and it extract all the candidate regions from an input image. Then, the model only retains 36 regions with the highest confidence and keep the semantic class distribution of each region from them. What is important is that the model use the mean-pooled convolutional features as visual features, not easily selects features from those 36 regions. Let's use to denote the vectors of the visual features, where refers to the visual feature of the i-th region. In order to guarantee the consistency between the dimension of each vectore of visual feature and language feature, the model also adopt the linear layer to project visual features to d-dimensional vectors, denoted by . Second, for text, the method for feature extraction is easier. The model uses the token embedding to transform the tokens of each review to d-dimensional vectors. Also, it will keep the indexes of each token for the following pre-training task: Textual Aspect-Opinion Extraction. Because the visual and language features are input to the same BART Encoder, it is necessary to mark the boundaries to distinguish the type of the features. In this essay, Ling et al. sets the symbols: <img>, </img>, <bos>, <eos> for distingushing visual and text features, respectively.
# Pre-training
The model is pre-trained by 5 pre-training tasks:
- Masked Language Modeling
- Textual Aspect-Opinion Extraction
- Masked Region Modeling
- Visual Aspect-Opinion Generation
- Multimodal Sentiment Prediction
Likewise, the BART Decoder is also shared, thus there are 5 groups of symbols in the pre-training steps, too. Table. 2 shows these symbols and their usage.
| symbols | usage |
|---|---|
| <bos><mlm><eos> | for Masked Language Modeling |
| <bos><aoe><eos> | for Aspect-Opinion Extraction |
| <bos><mrm><eos> | for Masked Region Modeling |
| <bos><aog><eos> | for Aspect-Opinion Generation |
| <bos><msp><eos> | for Multimodal Sentiment Prediction |
Now, let's analyse the detail of five pre-training tasks respectively.
# Textual Pre-training

Textal Pre-training consists of 2 pre-training tasks: Masked Language Modeling and Textual Aspect-Opinion Extraction. For Masked Language Modeling, the specific strategy of masking is similar to the strategy of BERT: the model will randomly masks 15% input tokens with the symbol [mask] and try to revert them to original tokens by "reading" the context. The loss function of Masked Language Modeling is:
For Textual Pre-training, the model treats it with the Index Genertion task, which means the model will output the indexes sequence of the targets like aspect and opinion terms after receiving the tokens sequence. Similarly, Ling et al. define the symbol "<sep>" to divide the aspect and opinion terms. Let's take the input sequence of Figure. 3 as the example, when the model received the sequence "Best concert opening of Justin Bieber", the decoder should ouput the range of indexes of "Justin Bieber"(5 to 6) and "best"(1 to 1) because they are the aspect and opinion terms in this sequence. In fact, the model relies to the softmax layer to predict the distribution of the aspect and opinion terms in the sequence. Here are the equations:
where denote the output of BART Encoder and its textual part; is the previous output of BART Decoder(assume the model is in t-th step); Thus, means the output of BART Decoder in t-th step. For the second equation, denotes the embedding of the input tokens(In the example of Figure. 3, it is the embedding of "Best concert opening of Justin Bieber"); And is the output of BART Encoder after mean-pooling. For the last equation, denotes the embedding of the symbols(<bos>, <sep> and <eos>); And is the result of prediction. The loss function of Textual Aspect-Opinion Extraction is:
where $ O = 2(M + N + 1)$ is the length of Y and X denotes the multimodal input(M and N are the number of aspect and opinion terms in the sequence).
# Visual Pre-training

Like the procedure of Textual Pre-training, Visual Pre-training divides into 2 parts: Masked Region Modeling and Visual Aspect-Opinion Generation. For Masked Region Modeling, inspired by Ju et al. what is as same with Masked Language Modeling is the strategy of masking: the model will randomly masks 15% regions of the input images. However, something different is the action of the masking: the masked regions will be replaced with zero vectors. Specifically, for the input of the BART Decoder, the model will represent each masked region with <zero> and each remaining region with <feat>. After that, an MLP classifier is stacked over the output of each <zero> to predict the semantic class distribution. Here is the loss function of Masked Region Modeling:
In this equation, let's use and to denote the class distribution detected by Faster R-CNN and the predicted class distribution of the z-th masked region, respectively. The function means that computing the KL divergence of these two class distributions. For Visual Aspect-Opinion Generation, the goal is generating the aspect-opinion pairs by the input images. In this essay, Ling et al. decide to let the model generate adjective-noun pair(ANP) to achieve this goal(the adjectives and nouns can be treat as opinion and aspect terms). Thus, they utilize a tool named DeepSentiBank to predict the class distribution over 2089 pre-defined ANPs. The ANP with the highest probability is selected as the supervision signal of the AOG task. With the visual aspect-opinions upervision, the AOG task can be formulated as a sequence generation task. Let's use to denote the sequence of the input ANG tokens( is the number of the input tokens). The model takes the multimodal encoder output and the previous decoder output as inputs, so the prediction of the token probability distribution is:
where denotes the embedding matrix of all tokens in the vocabulary of the pre-defined ANPs. And the loss function is:
# Multimodal Pre-training
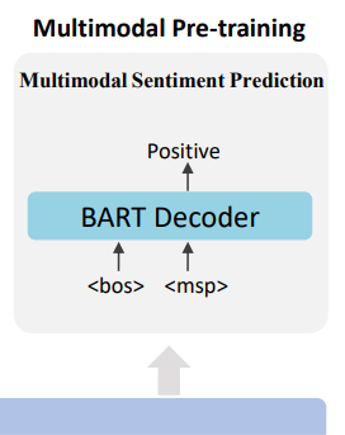
There is only a task in Multimodal Pre-training: multimodal Sentiment Prediction. Ling et al. model the task as a classification task, which focuses on classifying the specific sentiment polarities of the aspects. The input of the BART Decoder is two special tokens <bos> and <msp> and the prediction of sentiment distribution is as follow:
where is the embeddings of two special tokens. The loss function is:
where is the golden sentiment annotated in the dataset.
# Full Pre-training Loss
To find out which pre-training task is the most important, Ling et al. set 5 hyperparameters to the final loss function:
Why the model parameters will be optimized is that control the contribution of each task.
# Experiment
In this section, we talk about the detail of the experiment, including the datasets used in pre-training and training, as well as the results of the proposed approach for different tasks.
# Dataset


Let's compare the number of data between Table. 3 and Table. 4, and it's obvious that MVSA-Multi dataset contains more and more data. That is the reason why Ling et al. treat it as the pre-training dataset. However, another point should be attention with is MVSA-Multi is a coarse-grained dataset, so it's easier to get its data.
# Result
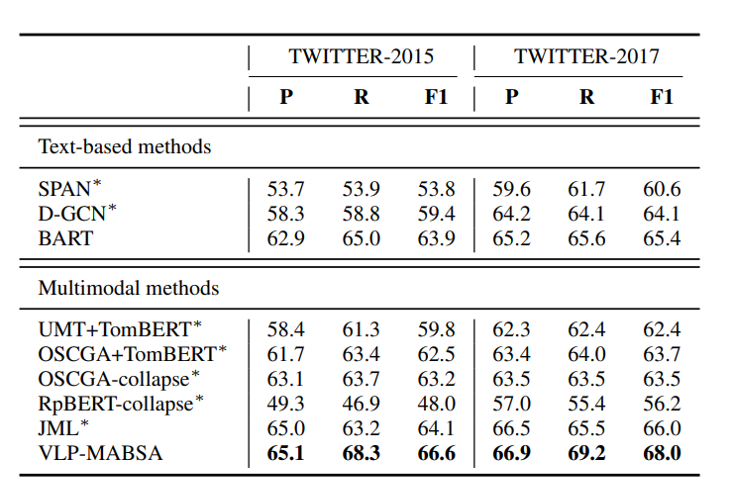
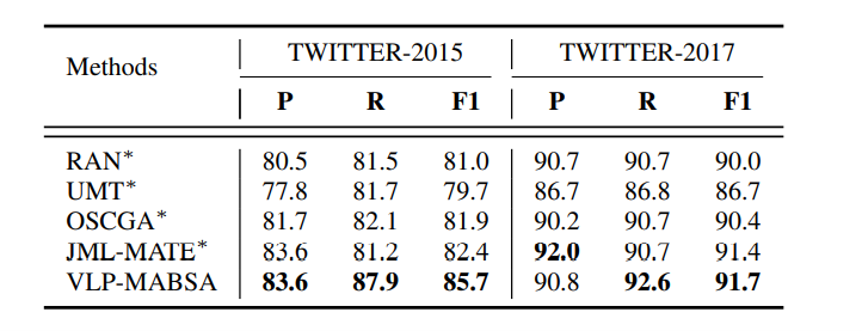
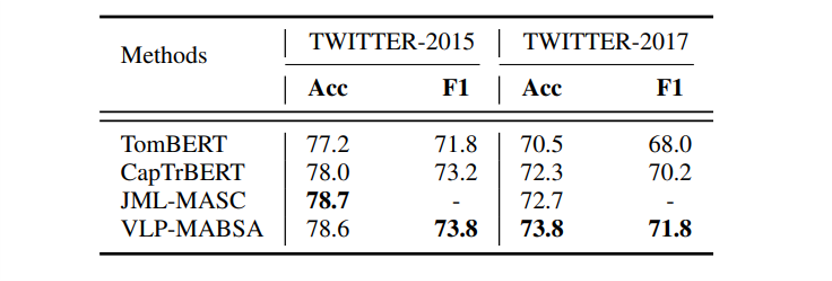
Here are the results for Joint Multimodal Aspect-based Sentiment Analysis(JMASA), Multimodal Aspect Term Extraction(MATE) and Multimodal Sentiment Classification(MASC), and VLP-MABSA is the model from the proposed approach. VLP-MABSA performs best for JMASA at Twitter 2015 and 2017 dataset, whether the accuracy or the F1 score shows. And VLP-MABSA get the higest F1 score for MATE and MASC at both two dataset. That means we can treat the proposed model as SOTA model.
# Ablation Study

In this section, we seek about the how will each pre-training task affect the model. As what the Table. 8 shows, the AOE and AOG pre-traning tasks are important to improve the model, and they are something new to pre-trained language model, too. I think that is one of the reasons why VLP-MABSA can be the SOTA model.
# Reference
[1] Alan Ritter, Sam Clark, Mausam, and Oren Etzioni. 2011. Named entity recognition in tweets: An experimental study. In EMNLP.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL, pages 4171–418
[3] Xincheng Ju, Dong Zhang, Rong Xiao, Junhui Li, Shoushan Li, Min Zhang, and Guodong Zhou. 2021. Joint multi-modal aspect-sentiment analysis with auxiliary cross-modal relation detection. In Proceedings of EMNLP
[4] Tao Chen, Damian Borth, Trevor Darrell, and ShihFu Chang. 2014. Deepsentibank: Visual sentiment concept classification with deep convolutional neural networks. arXiv preprint arXiv:1410.8586.