
本文章主要参考自以下原博客,本文内容仅供参考,有表述欠缺妥当之处,敬请原谅: https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html
# 序言
在序言中,本文首先记录了关于“什么是有监督、无监督、自监督学习”、“什么是对比学习”以及“为什么需要自监督学习”这三个问题的解答,以方便下文对于对比自监督学习(Contrastive Self-Supervised Learning)的阐述。
# 什么是有监督、无监督、自监督学习?
在机器学习领域中,这三个术语均为训练机器按照所提供的数据进行学习的方式,我们希望机器能够从这些数据中获得一些展现智能的能力,比如说自动分类文本、图片、语音等能力。根据所提供的数据类型,我们可以为机器指定以下的训练方式:
- 有监督学习:提供给机器的数据是带标签的(with labels),比如说我们有一张 Tom and Jerry 中的汤姆猫的照片,同时我们标注了这张照片是汤姆猫,当我们将这样的带标签的数据提供给机器学习时,就是让机器进行有监督学习。
- 无监督学习:与有监督学习的理念相反,我们提供给机器的数据是不带标签的(without labels),让机器自行领会其中的真意。
- 自监督学习:实际上,自监督学习是无监督学习的一种,其核心思想是让机器自己为无标注的数据“做标注”。在这种情况下,机器会通过根据已经“看”过的数据样本来判断当前正在“看”的数据与之前哪个数据很像,并试图将标为同一类,以“模仿”有监督学习。

如果在给机器“看”这张照片的时候,就已经告诉它这是 Tom 时,就是有监督;没告诉就是无监督;在没告诉的情况下,机器能够自行通过之前“看”的图片,将这张图片归类为 Tom 的话,就是自监督。图片来源:百度图片 (opens new window)
# 什么是对比学习?
我们先以一个简单的例子理解对比学习:首先,邀请一位非专业画师单凭记忆画出一元美元纸钞的样子;再把一张真正的一元美钞给画师以供其临摹,两种情况下画出来的结果是大相径庭的,如下图:
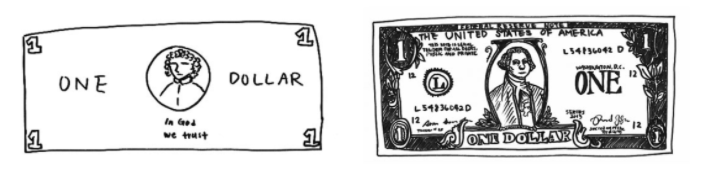
左边是没有实物参照的情况下,画出的结果;右边是有实物参照的情况下,画出的结果。图片来源:Epstein, 2016 (opens new window)
虽然在细节上,这两张图差别很大,但我们都能够很容易地理解它们实际上都是在画一元美钞。这说明我们在识别一个东西的时候,并不依据它的所有特征的,即我们不需要关心它的所有细节,有个大体的模样我们就能够识别它是什么。那么,我们是否可以以同样的道理去指导机器学习足以区分物体的特征呢? 同样是以这个例子解释,即使看过无数次一元纸币,但仅凭印象将它画出来,大多数人也只能画出一个模棱两可的样子。可这也足够我们去将其与其他物体区分出来,比如说我们通过这样模棱两可的简画就可以认出它是一元纸币,而不是足球、苹果或是小狗小猫。那么,同样的道理,我们不能强迫机器去关注一个物体的所有特征,只让它关注能帮助它区分具体物体的特征就能达到我们的目的了。 对比学习就是参考了这样的思想,对某个数据样本,我们使用数据增强的方式,为其构造一个与其类似的样本和若干个与其不像的样本,让机器学会正确对待相似、不相似的情况。在掌握了这样的方法之后,机器一般就能够提升进行分类等工作的能力了。
# 为什么需要自监督学习?
写到这里,可能很多人会想,既然有监督学习那么省事,也不用教机器去学对比学习,那么为什么还要研究自监督学习呢?首先,我们需要认识到仅依赖有监督学习所遇到的问题:
- 有标签的数据不是凭空就能获取到的,往往需要进行专业的人工标注工作,在此之后才能获取到的;然而这样的有标签的数据与无标签的数据相比,获取成本高,且数据规模小。
- 在有监督学习中,基础数据(如文本、像素)与稀疏的标签相比,具有更丰富的语义信息;因此单纯的有监督学习常常需要大量的带标签数据,训练出来的模型也很难做迁移学习
- 在高维度的情况下,有监督学习获取标签的边际开销比强化学习(Reinforcement Learning) 还要高
而针对带标签的数据规模并不大的任务而言,自监督学习能够解决模型强度与数据规模成正比的问题。
# 自监督学习
在目前,自监督学习主要分为 生成型(Generative) 和 对比型(Contrastive) 两种。这两种形式的不同点在与损失函数的计算方式:
图中 Generative/Predictive 为生成型的自监督学习,而 Contrastive 为对比型的自监督学习,正如图片所示,两者的损失函数计算重点分别在于 输出(output) 和 表示(representation) 两个方面
- 生成型:重点在与重构数据;以文本句子为例,生成型的自监督学习具体会将句子中的某个词语替换(通常将其以某种特殊的符号替换),再让模型进行重构。以句子 “I like climbing mountains in October” 为例,模型将 climbing 替换成字符 MASK 后需要根据替换后的句子进行重构,在这个过程中模型会预测很多个词尝试复原回原来的句子,以此不断贴近 climbing 这一个词,这一系列的举措的量化标准即为损失函数的计算原理。
- 对比型:重点在于构建正、负例,并与原本的数据样本进行对比,以此将正例样本划为与原本数据相似的一类,而将负例样本划为不同的一类。同样以句子 “I like climbing mountains in October” 为例,模型将构建正例样本 I like climbing hills in October 和若干个负例样本,如 I forgot to buy some apples last night,目的是让模型理解正例与原句子意思相近而负例与原句子意思不同,这一系列的举措的量化标准即为损失函数的计算原理。
# 对比学习
在这一节中,本文记录了 对比自监督学习(Contrastive Self-Supervised Learning),即对比学习的原理及应用案例。
# 原理
实际上,对比学习的原理可以用一句话解释:构建一个 Softmax 函数,用于区分正、负例,使得原数据样本与正例的得分十分大而与负例的得分十分小,即:
在上述不等式中, 函数为计算数据样本之间相似度的函数; 与 分别表示正例、负例,它们实际上分别是被构建的与 相似、不同的数据样本。 由于应用了 Softmax 函数 对正、负例进行分类,为了让正例得分尽可能大而让负例得分尽可能小,对比学习的损失函数为:
在这个损失函数式子中,我们将求向量内积作为 函数,分母中的 项均为负例,符号 为求数学期望。我们将这个损失函数与 Softmax 函数 的损失函数比较一下以加深理解。
# 与 Softmax 函数损失函数的对比
以第 i 类为 Softmax 函数 输出的正确类别,那么其概率 为:
其中 为输出的所有类别数目, 为第 i 个节点输入到 Softmax 层 的值。又因为 Softmax 函数 是以交叉熵计算损失函数,其计算式子为:
其中, 为当前标签编码取值(通常为 one-hot 编码形式);对比 Softmax 函数 的损失函数和对比学习的损失函数,可见两者形式相似,则不难理解为对比学习实际上是以 Softmax 函数为基础的。
# 应用
对比学习首先在计算机视觉(Computer Vision)领域得到广泛应用。这里以 Deep InfoMax(Hjelm et al., 2018 (opens new window)) 为例,该方法的原理如图所示:
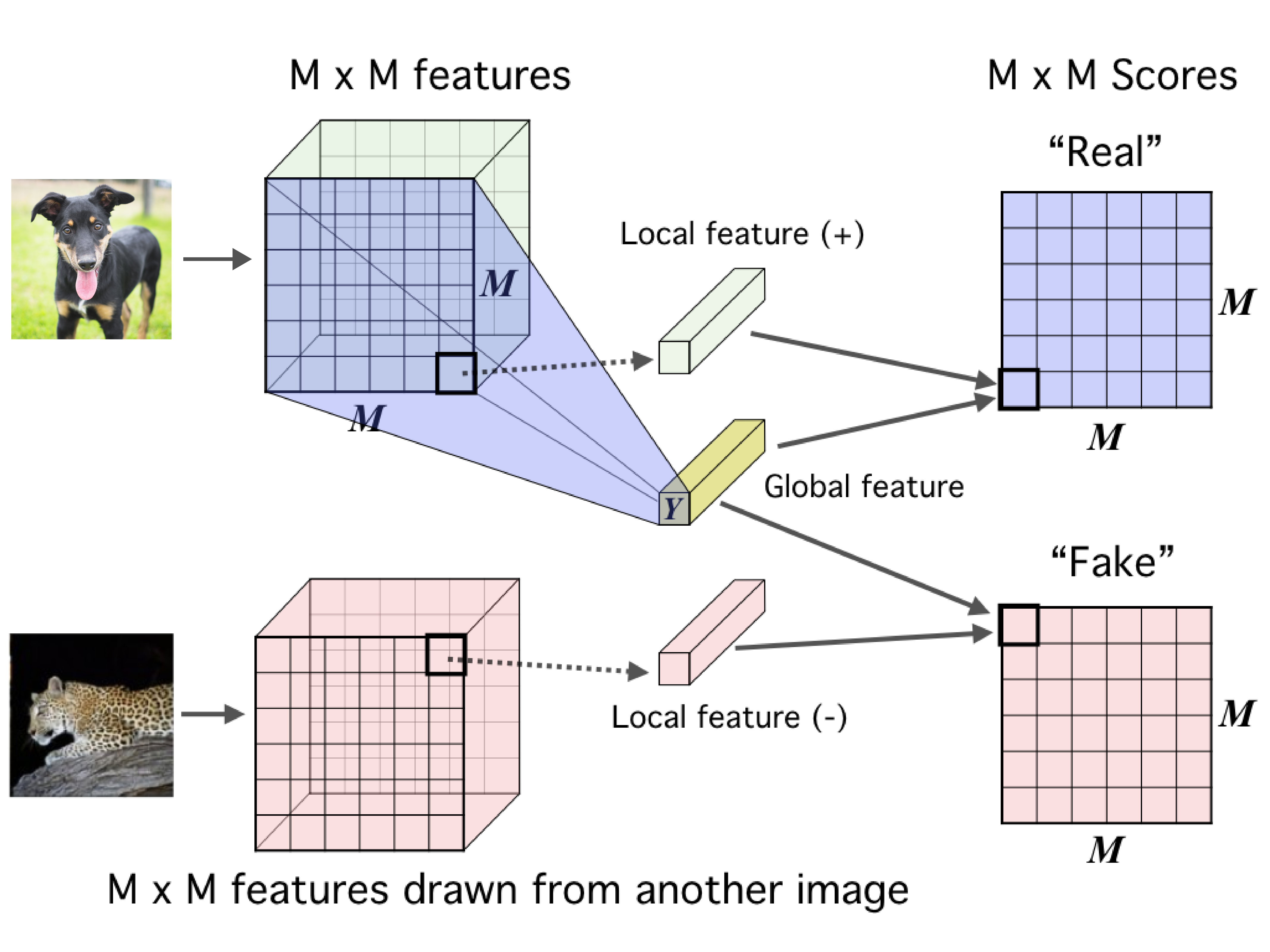
本方法的主要思想是将原数据样本图片的一部分特征提取出来,作为“局部正例特征”;将与其完全不同的另外一张图片的一部分特征也提取出来,作为“局部负例特征”;最后通过 卷积神经网络(CNN) 将原图片输出为一个与局部特征维度相同的“全局特征”,通过对比“全局特征”与“局部正例特征”、“局部负例特征”实现对比学习。 而在文本、音频这样的序列(Sequence)数据处理领域中,也有以音频处理中的 Contrastive Predictive Coding(van den Oord et al., 2018 (opens new window)) 为例的应用,该方法的原理如图所示:

本方法的主要思想为将一段音频划分为若干个数据段,当模型处理到第 个数据段时,将其之后的 个数据段作为正例,而将噪音语音作为负例实现对比学习。