
TextCNN
原论文:Convolutional Neural Networks for Sentence Classification
作者:Yoon Kim
发布时间:2014年
Seq2Seq
原论文:Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
作者:Kyunghyun Cho、Dzmitry Bahdanau、Fethi Bougares Holger Schwenk、Yoshua Bengio
发布时间:2014年
本文参考内容:
# 序言
因为最近事情比较繁多,很久没有更新了,这几天特地跟进一下文章撰写进度。本篇文章我将简略地总结一下两个重要的模型:TextCNN 与 Seq2Seq,其中提出 TextCNN 的论文作者将在计算机视觉(Computer Vision, CV)中常用到的卷积神经网络(Convolutional Neural Networks, CNN)进行微调,使其能够用于自然语言处理的文本分类任务,并通过了许多实验证明了其可行性;而提出 Seq2Seq 的论文作者从机器翻译(Machine Translation)任务出发,提出了能够有效编码输入句子的语义与句法信息的方式,并将这些信息用于翻译输入的句子为目标语种的相同含义句子。 另外,针对于 Seq2Seq 模型,后人还提出了一个重要的辅助机制——注意力机制(Attention Mechanism),以此提升其性能,而注意力机制更是启发了后来的 Transformer 模型。
# TextCNN
在本文中,作者首先阐述了训练词向量的本质——将本身是 |V|(V 为语料字典大小)维的稀疏编码向量(即 one-hot vectors)通过神经网络模型的隐藏层转换为低维的向量,而在这个过程中,训练词向量的模型(无论是 Word2Vec, GloVe 还是其它模型)实际上在完成的工作是提取语料中的语法特征,从而将语法特征相近的 words 之间距离也较小。 尽管在此之前,CNN 在计算机视觉、语音识别领域已大放异彩,同时也有研究人员使用 CNN 完成自然语言处理任务,但本文作者在 CNN 的基础上进行了模型结构微调,使得该模型能够有效地在多个 NLP 任务中都取得优异的结果。 下面我们来分析一下 TextCNN 的模型结构:

论文中的 TextCNN 结构采用了 2 个 "channels",虽然 "channel" 术语参考自计算机视觉领域,但在这里的意思是在卷积层中使用 2 个卷积核(kernel)提取特征
对于一个经过 embedding 的句子 而言,假设它由 n 个 words 组成,句子中的第 i 个 word 为 ,那么 可以看作是:
如果 embedding 后的词向量维度为 k,则句子 可看作是 维的矩阵。又因为句子不像图片那样由 RGB 三个 channels,所以我们也可以认为句子仅包含一个 "channel"。而在设置卷积核 时,我们假设长度为 h,宽度保持为与词向量的长度相等的 k,则 ,则句子的第 i 个特征 为:
默认卷积运算的步长为 1,则句子 可以得到特征向量 :
在得到了句子的特征向量 后,TextCNN 再将其传入最大池化层,把 中的取值最大的元素作为句子最终的表示形式(sentence representation)。需要注意都是,如果卷积层只是用了一个卷积核,那么 的元素为常数;如果卷积层使用了多个卷积核,则 的元素为向量。 最后,将句子表示传入到线性层,经过正则化后通过 softmax 层能过得到句子的文本分类概率分布。
# 实验
由于 TextCNN 与 RNN(在本次实验中,我们选用了 Bi-LSTM 作为 RNN 模型的实现方式) 都能完成文本分类任务,我在实验过程中分别搭建了这两个模型,并令它们均在 AGNewsDataset 数据集上进行文本分类实验,实验结果如下:
| Accuracy | F1-score | support | |
|---|---|---|---|
| TextCNN | 0.88 | 0.88 | 7600 |
| Bi-LSTM | 0.90 | 0.90 | 7600 |
由实验结果可见,虽然在实验的短文本分类任务(因为本实验设定的最大文本长度为 25 )上,TextCNN 所取得的效果并没有优于 Bi-LSTM 模型,但两者的差距也并不大;下表为该两个模型在具体的 4 种新闻类别中的分类结果(均以 F1-score 作为评判指标):
| World | Sports | Sci/Tech | Business | |
|---|---|---|---|---|
| TextCNN | 0.88 | 0.94 | 0.84 | 0.84 |
| Bi-LSTM | 0.91 | 0.95 | 0.87 | 0.86 |
由 TextCNN 和 Bi-LSTM 不同的模型机制推测,我们认为是因为前者提取的文本特征是按照每次 Kernels 所覆盖的范围决定的,即每个 $ c_i $ 都只是在当前 word 的一定范围上下文得到的,且句子表示是 中取值最大的元素,实际上也是某个 word 的特征向量,而 Bi-LSTM(RNN)则是通过句子中的所有 words 得到最后的 hidden_state 作为句子表示,可以理解为它使用了整个句子所有 words 的语义信息
# 特点
在吴恩达老师的深度学习课程中,关于 CNN 的模型优势被总结为以下两点:
- 参数共享(Parameters Sharing)
- 对于卷积层的 Kernels,它们不仅可以获取当前 word 的特征,还能够共享到其它 words 的特征提取工作中;这意味着 CNN 模型在计算参数时,实际上就是在计算各个 Kernels 的参数,并通过 back propagation 来优化它们的参数,这使得 CNN 的参数规模较小
- 稀疏链接(Sparsity of Connections)
- 正如我们在实验分析中所推测的,TextCNN 每次计算一个特征时只是在一定范围的 words 词向量中进行计算的,而在计算机视觉领域中,CNN 获取某个图片特征时,也是在一部分像素取值内计算的;这使得 CNN 能够并行、高效地计算特征值
# Seq2Seq
Seq2Seq 模型又称为 Encoder-Decoder 模型,该模型架构为 2 个 RNN 组成,由于这 2 个 RNN 分别承担编码、解码任务,所以可以将它们分为 Encoder 与 Decoder。 在这篇论文中,作者提出了这种模型并将其运用到机器翻译领域(Machine Translation);其核心思想为通过作为 Encoder 的 RNN 编码输入的待翻译文本序列,在这个过程中 Encoder RNN 将学习到待翻译文本序列的语义和句法信息,而这些信息将会由 Encoder RNN 所输出的最后一个 hidden state() “携带”着;而作为 Decoder 的 RNN 除了接收所输入的文本序列外,还接收了 Encoder RNN 所输出的最后一个 hidden state,目的是让 Decoder 学习到原待翻译文本序列的语义与句法信息,再根据所希望得到的目标文本序列的监督令 Decoder 能生成翻译结果。 Seq2Seq 模型的大体结构如下图所示:

通过图中的箭头指向可知,Seq2Seq 模型首先将输入文本序列编码为向量 c,之后不断更新向量 c 与接收上一步生成的 word 来实现当前 word 的生成,进而完成整个文本序列的生成
对于 Encoder: 在每个时间点 t 里,当前的 hidden state 会根据上一个时间点的 hidden state 与当前时间点 t 的输入 进行更新
其中, 为一个非线性的激活函数,它既可以简单地设为 sigmoid 函数,也可以更复杂地设为 LSTM 函数。
对于 Deocder: 由于在每个时间点 t 里预测此时生成 需要根据前面的 ,所以可将预测 的概率分布记为条件分布式 ;而对于长度为 的词典,预测 实际上可以视为根据 进行 K 分类问题。因此,在引入 softmax 函数后,上述条件分布式 可以进行以下等式求解:
在上式中,我们考虑了词典中所有 words 被预测的概率(),同时 是线性变换矩阵 的第 j 列;再将 到 的条件分布式整合,能够求得生成特定文本序列 的概率分布式为:
Decoder 的输出机制: 由于 Seq2Seq 模型不需要规定输入文本序列与输出文本序列的长度一致,且能够将任意长度的输入文本序列编码成固定长度的 context vector,因此机器翻译任务可以理解为求得概率分布 $ p(y_1, ..., y_{T'} | x_1, ..., x_T) $ ,其中 T 与 T' 不一定相等。由上述的模型架构图可知,Decoder 在时间点 t 中生成文本 依靠于 的取值,又因为 会随 与 而更新,因此有以下式子:
其中, 与 非线性的激活函数,而由于函数 还需要求出文本序列的概率分布情况,因此需要额外增加 softmax 函数。
联合训练: 由于整个 Seq2Seq 模型由两个 RNN 组成,而训练阶段模型整体的损失函数是通过计算 Decoder 所生成的文本序列与目标文本序列的交叉熵所得,因此 Encoder 与 Decoder 是联合训练的;在这种情况下,模型训练的目的是将以下条件似然函数最大化,并取达成该目标的 :
上式的 为模型的参数,序列对 为训练集数据里的原句文本及其翻译结果文本。
# GRU
另外,这篇论文还提出了一个类似于 LSTM 的变体 RNN 结构——门控制循环单元(Gate Recurrent Unit, GRU);该结构分为 undate gate 与reset gate,根据两者的取值情况,RNN 在计算 hidden state 时也会发生变化,以下是 GRU 的结构图:
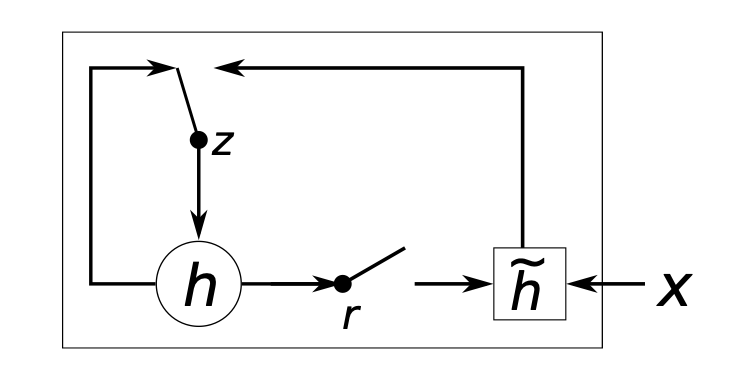
假设整个 RNN 由 n 个单元组成,且这些单元均以 GRU 的形式计算每一步的 hidden state,则我们取第 j 个单元(对应输入的文本序列中的第 j 个 word)为例分析,它的 reset gate 和 update gate 分别记为 与 ,那么 的取值由下式决定:
在这个式子中, 是 sigmoid 函数, 与 分别为输入的文本序列向量及上一个 hidden state,而 即为文本序列中的第 j 个 word;而 均为可学习的权重矩阵。与 的计算方式相似, 由以下式子计算而得:
在完成 reset gate 与 update gate 的计算后,第 j 个 GRU 单元输出的 hidden state 为:
在上面的式子里,符号 为向量点乘(即向量间对应位置的元素相乘);当 的某些元素为 0 时, 中的对应位置的元素也相应地并改为 0,这意味着此时 RNN 模型一定程度上忽略了上一个 hidden state 而仅根据输入数据计算当前的 hidden state;这样做能够让模型抛弃一部分与后续计算无关的信息;而就 而言,它能够控制上一个 hidden state 对当前 hidden state 计算的影响程度,即影响 hidden state 的更新情况。
为什么需要 GRU ?
本文作者提出,在实际的实验运用中,GRU 的计算结果与 LSTM 相似,但相对而言 GRU 更容易实现且计算量更小;而对于 RNN 模型而言,如果输入的文本序列长度较小或较长(对应 RNN 模型的时间步数较少或较多),都可能会出现梯度消失的情况,而 GRU 与 LSTM 均是解决这个问题的有效方法。
# 特点
- Seq2Seq 模型在处理文本序列时,能够回避文本长度与词序的限制,即输入到模型的文本序列长度及其词序可以与模型输出的文本序列不同,这一个重要的特点非常适合于解决机器翻译问题
- 不同语言之间可能存在部分语法规则不同的问题,但实际上也存在着语种之间通用的语义知识和句法结构特点;而 Seq2Seq 模型的 Encoder 对这些通用的知识进行编码,使得 Decoder 能够学习到并运用于生成另外一个语种的,具有相同语义、句法信息的文本序列,这样的思想能够帮助我们研究自然语言生成(Natural Language Generation, NLG)问题
# 缺点
针对于 Seq2Seq 模型希望将输入的文本序列编码为固定长度的向量(实际上就是构建 RNN 模型时所设定的隐藏层维度大小)以实现编码语义与句法信息的特点,当需要编码的序列长度较长时,即使 Decoder 接收到了 Enocder 所传入的 hidden state 向量,也很可能不能完整地解码出原文本序列的文本信息(因为长文本的文本信息往往十分复杂)。 另外,由于 Seq2Seq 模型的 Decoder 在生成每个 word 的时候是将前一个生成的 word 和前一个 hidden state 作为输入,在这种文本生成机制下,生成当前步骤的 word 所需要的文本信息往往只是原文本序列的一部分文本信息,如果能够让 Decoder 在每一次生成 word 时都更关注与目标输出相关的文本信息,那么模型的准确率就能够得到提升。
# 改进
基于上述需要改进的两点,研究人员提出了在 Seq2Seq 模型的基础上增加注意力机制(Attention Mechanism)的方案,在注意力机制的辅助之下,Seq2Seq 模型的文本生成准确度得到了提升;而注意力的重要性也因此被研究人员们广泛关注,其重要应用模型为之后 Google AI 团队所提出的著名 NLP 模型 Transformer。