
经典论文阅读:Transformer, BERT 和 RoBERTa
Transformer 原论文:Attention is All You Need
作者:Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
发布时间:2017年
BERT 原论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
作者:Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
发布时间:2019年
RoBEARa 原论文:RoBERTa: A Robustly Optimized BERT Pretraining Approach
作者:Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov
发布时间:2019年
# 引言
随着预训练语言模型在 NLP 的不同领域中大放异彩,当前的各项 NLP 任务几乎均围绕着 “预训练语言模型+微调”(Pre-training + task-specific fine-tuning) 的方式改进实验模型;本文从目前广为人们所知的预训练语言模型(BERT 及其变体 RoBERTa)出发,首先介绍它们所使用的模型架构 Transformer,再依次说明它们是如何从 Transformer 中衍生而来,及它们发生变化的目的及达成的效果。
# Transformer
Transformer 模型实际上是一个用于机器翻译(Machine Translation)领域的 seq2seq 类型模型;与之前研究所提出的 seq2seq 模型相同的是,Transformer 所接收的是一个输入序列(input sequence),输出则是经过编码与解码(encode & decode)后得到的输出序列(output sequence);而不同点在于,Transformer 的主体架构不是 RNN 或 CNN ,而是其论文标题所提及的 Attention Mechanism。下图为 Transformer 模型的整体架构,在介绍 Transformer 架构的不同部分前,我们先探究为什么论文作者放弃 RNN 或 CNN 结构而选用 Attention Mechanism 作为模型主要机制。

# Why Not RNN or CNN ?
在 Transformer 问世之前,我们常常使用基于 RNN 或 CNN 的模型完成具体的 NLP 任务;RNN 的特点是可以以序列的方式计算文本特征,这对于有上下文(context)概念,且需要提取语义信息(semantic information) 的文本数据来说是十分切合的;而 CNN 的特点是多个 kernels 可以并行地进行卷积计算,每个 kernel 在文本序列中都会覆盖一定范围的词(word),实际上也起到了提取语义信息的作用。 尽管引入了 Attention Mechanism 能够让 RNN 与 CNN 能够更关注文本序列中的某些词,从而提高模型执行不同任务的结果准确度,如在机器翻译任务中,模型应该更关注序列中的某些重要单词(如名词、动词等)才能得到更准确的翻译结果;但 RNN 与 CNN 相对于 Transformer 所基于的 self-attention mechanism 分别有如下缺点:
- 对于 RNN 而言,因为每次计算当前 word 的特征向量时,需要接收上一次计算的 hidden state 作为输入,因此 RNN 在计算上是不可并行的;当基于 RNN 的模型需要处理数据规模较大且序列长度较长的文本时,计算开销的时间较长;另外,RNN 接收上一次计算的 hidden state 作为输入的特点意味着每次计算当前 word 的特征向量时,所使用到的上下文信息有限,很可能会忽略了与当前 word 距离较远的 words 的信息。
- 对于 CNN 而言,尽管每个 kernel 的卷积计算能够并行执行,但因为 kernel 所覆盖的文本范围有限,即使设计多个不同大小的 kernel 以实现使用不同长度的上下文信息来计算文本序列的特征向量,也很难实现像 self-attention mechanism 那样每个当前处理的 word 与序列中的其他所有 words “交互”的效果。
# Components
从整体上看,Transformer 由 Encoder 与 Decoder 两部分组成,它们各自的组成结构如下:
- Transformer Encoder
- Embedding 层(包括 Positional Encoding )
- 多层 Multi-Head Attention 层(包括 Residual Connection 与 Layer Normalization )
- 多层 Feed Forward Neural Network (包括 Residual Connection 与 Layer Normalization )
- Transformer Decoder
- Embedding 层(包括 Positional Encoding )
- 多层 Masked Multi-Head Attention 层(包括 Residual Connection 与 Layer Normalization )
- 多层 Multi-Head Attention 层(包括 Residual Connection 与 Layer Normalization )
- 多层 Feed Forward Neural Network (包括 Residual Connection 与 Layer Normalization )
- 线性层( Linear )与 Softmax 层
由 Figure. 1 可知,Multi-Head Attention 层是整个模型的主要模块,且在 Encoder 与 Decoder 两部分中都有广泛的使用,为在之后理解整个模型的工作流程,我们首先探究 Multi-Head Attention 层的工作细节。
# Multi-Head Attention
Scaled Dot-Product Attention 对于 Multi-Head Attention 层,我们首先需要了解的是它的核心机制—— self-attention mechanism。相比于 CNN 与 RNN,self-attention mechanism 的核心思想是计算当前经过 Embedding 的 word vector 与在相同序列中的其他 word vectors 的 Scaled Dot-Product Attention;简而言之,对于每个 word 记为 ,有三个经过线性变换后的向量 和 ,而 需要与 和序列中其他的 所衍生的 进行向量点乘,所得的结果分别与 和序列中其他的 所衍生的 相乘,最终将这些向量相加得到 self-attention mechanism 中对应于 的输出 ,如下图:
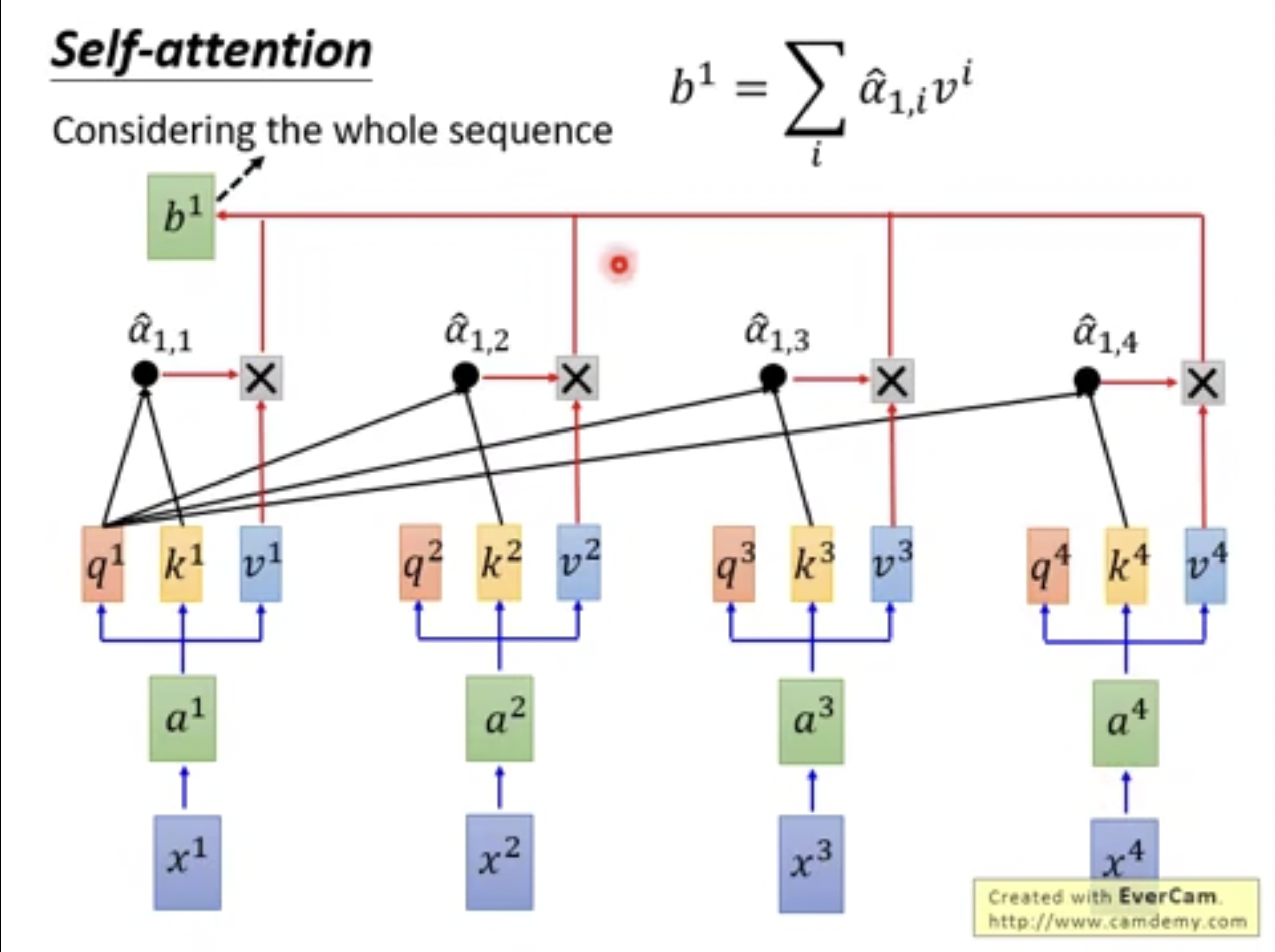
由于计算向量点乘是可以并行进行的,所以文章中将所有 汇总为三个矩阵 和 ;然而,上面的运算仅仅是做了 dot-product,并没有体现到 Scaled Dot-Product Attention 中的 scaled,实际上它代表的是在 与 进行向量点乘之后,需要除以一个 的因子,目的是防止向量点乘的结果在后续传入 softmax 函数后,反向传播算法所计算的梯度值过小。最终 Scaled Dot-Product Attention 的整个过程可以由下式表示:
整个计算 Scaled Dot-Product Attention 的过程如下图所示:

为什么以 dot-product 作为计算 attention 的方式? 实际上,计算 attention 的方式还可以是使用只有一层 hidden layer 的 feed forward network,并令其接收 Q,K,V 作为输入,但由于这种方式的并行效率不高,且矩阵计算在 numpy 等实现工具包中已经得到很成熟的效率优化。
Multi-Head Attention 相比于将 设为一个较大的值而仅计算一次 attention 值,Transformer 引入了 Multi-Head Attention 的方式并根据注意力头的数量计算多次 attention;根据上文所提及的公式,计算 attention 的整个过程实际上是在做矩阵运算,所以将 self-attention 层划分为多个同时计算的并行子层并不会影响效率。 在实际的 Transformer 模型中,Multi-Head Attention 层由 h=8 个注意力头对应的 8 个字层组成,相应的, 也会由原来的与 大小相同改为 ,整个过程如下式:
其中,,,;最终,可以用一个流程图表示 Transformer 中的 Multi-Head Attention 的整个工作流程:

# Position-wise Feed Forward Network
为了让 Multi-Head Attention 层输出的由输入文本序列的每个 word 对应的注意力加权向量具有位置意识(Position-wise),论文还提出了在 Multi-Head Attention 层之后加入 Feed Forward Network 的想法。对于该 Feed Forward Network,输入的矩阵需要做 2 次线性变换,分别为将矩阵维度变为 和还原为 ,而在两次线性变换之间,输入数据还做了一次非线性变化,在论文中作者所使用的为 RELU 函数,因此有:
# Embedding 与 Positional Encoding
在向 Encoder 与 Decoder 输入数据前,文本序列的每个 word 都需要经过 Embedding 层转换为词向量;由于 self-attention mechanism 的特性,实际上序列中的 word 因为与其他所有的 words 都计算了 attention 值,所以相对而言丢失了文本序列各 word 的顺序信息(order information)。 为补充顺序信息,论文作者提出使用三角函数模拟还原文本序列中各 word 的位置顺序,具体做法为计算一个 PE 矩阵,其中 :
其中, 代表当前 word 在文本序列中的位置, 与 大小相同。
# Masked Multi-Head Attention
Transformer Decoder 相比于 Encoder 多了一层 Masked Multi-Head Attention,但实际上它与 Multi-Head Attention 并无太大差异。因为在 seq2seq 模型中,预测当前输出的 word 只能与已经预测生成的 words 计算 attention 值,而 self-attention mechanism 默认是对整个序列计算 attention 值,因此需要令 Decoder 在训练阶段遮掩序列中的部分 words。
# 与预训练语言模型的关系
Transformer 在机器翻译领域中所取得的成功启发了后续研究人员对于语言模型(Language Model)的研究思路,其中 OpenAI GPT 参考了 Transformer Decoder 的架构,希望将 Transformer Decoder 预测下一个 word 的能力用于语言建模(Language Modeling)中(因为语言建模任务是让模型根据上文信息预测当前 word);而 BERT 则是 参考了 Transformer Encoder 的架构,同时以 Mask Language Modeling 作为语言建模任务。
# BERT
BERT 的全称为 Bidirectional Encoder Representations from Transformers,直观意思为 BERT 参考了 Transformer Encoder 的模型结构,而 Bidirectional 是相对于此前的 GPT 只通过上文信息预测当前词语的特点,BERT 是兼具了上下文信息以预测当前的词语,这是 Transformer Encoder 中的 Multi-Head Attention 子层作为基础实现的。
# 与 ELMO、GPT 等其他预训练语言模型的区别
实际上,将预训练(Pre-training)这一概念应用于语言模型的构建并非起源于 BERT;在此之前,已有 ELMO、GPT 等模型实现了预训练语言模型;预训练语言模型相对于此前广为使用的训练好的 Word2Vec、GLOVE 等语言模型,特点是每个词的对应词向量不会是固定好的,而是可以根据上下文的语义信息发生改变;比如说对于 "apple" 这个词,根据上下文语义信息,它可以是苹果这种水果,也可以表示为硅谷的一家科技公司名称。 而 BERT 与 ELMO、GPT 的区别在于以下几点,这也是 BERT 的作者团队所强调的 BERT 具有更准确的语言建模能力的原因:
- 与 ELMO 相比,BERT 的主体结构是基于 self-attention mechanism 的 Transformer Encoder 的结构,而 ELMO 是通过多层的 bi-LSTM 模型实现的;在上一节中,我们也谈到了 self-attention mechanism 对于 RNN 这样的序列模型而言,优势在于能够让每个 word 都充分利用到序列中上下文的其他 word 的信息,这使得 BERT 获取文本序列的语义信息特征的能力比 ELMO 更强
- 与 GPT 相比,BERT 的特点是选用了 Transformer Encoder 作为主体结构,而 GPT 则是参考了 Transformer Decoder 作为主体结构;在上一节中,我们也比较了 Transformer 的 Encoder 与 Decoder 之间的组成模块差异,其主要表现为 Decoder 的第一个子层为 Masked Multi-Head Attention,因为在计算当前 word 的自注意力时,Masked Multi-Head Attention 会掩盖序列的下文信息,因此 GPT 的语言建模过程是传统的从文本序列开头到结尾单方向的;而 BERT 所突出的 Bidirectional 的特点正是其在语言建模时是兼具从文本序列开头到结尾、从结尾到开头的两个方向的,因此 BERT 在预测当前 word 的时候,会同时使用到上下文的语义信息(实际上这也比较符合人类的思维,因为一个单词在句子中的出现位置往往也是要同时考虑上下文语境的)
# Why Pre-training?
不同的 NLP 任务所使用的数据集是不同的,同时不同任务的目标语言粒度也不同,比如说机器翻译的目标语言粒度为 sentence-level,而命名实体识别(Named Entity Recognition)的目标语言粒度为 token-level;因此具体到实际的 NLP 任务时,我们所使用的具体模型理应千差万别。但是,即使不同 NLP 任务有许多不同之处,有一个核心问题是共通的:构建准确的分布式表示(distributed representation)。 通过预训练语言模型,我们能够获取文本在大规模语料库中训练好的分布式表示形式使得针对特定 NLP 的研究能够专注于 task-specific 的方法及模型设计,当我们需要将具体任务的数据作为训练集数据时,BERT 只需要根据训练数据的特性修改少部分的模型参数;这也是 BERT 的作者团队提出了一种通用的 NLP 任务解决范式:Pre-training + fine-tuning。 而 BERT 所做的预训练是在大规模的语料库中完成两个无监督的预训练子任务,如 Figure. 5 所示:
- Masked Language Modeling(Mask LM)
- 这个子任务的目的是将预训练语料的每个句子的词语随机地替换为特殊符号 [MASK] 或另外一个在语料库中也出现过的实际词语,让 BERT 能够仅依据上下文信息还原原来的词语
- Next Sentence Prediction(NSP)
- 这个子任务的目的是在输入到 BERT 的两个句子之间插入一个分隔符号 [SEP],观察 BERT 能否根据该符号预测出这两个句子是否为预训练语料库中出现在同一个出处的连续的两个句子

# Fine-tuning
由于经过预训练过的 BERT 能够大致学习文本的语义信息,当我们需要根据特定任务的数据集训练 BERT 时,不仅能够调整 BERT 模型内部的参数,还可以增加额外的网络结构来完成具体任务。在论文中,作者以机器阅读理解(Machine Reading Comprehension, MRC)任务的 SQuAD 数据集作为例子,通过将 BERT 输出的 hidden state 输入到线性层与 softmax 层,预测文本序列中哪些 tokens 作为阅读理解问题的答案。
# 特殊符号[CLS]
BERT 在接收输入的文本序列后,会在序列的头部插入一个特殊符号 [CLS];这个符号会作为输入序列的其中一个元素参与到模型的整个计算过程,而作者认为在 self-attention mechanism 的特性下,[CLS] 能够学习到整个文本序列的语义信息,因此可以作为特征向量完成分类任务(实际上也能通过 fine-tuning 完成回归任务)。
# 与 Transformer Encoder 的细微差别
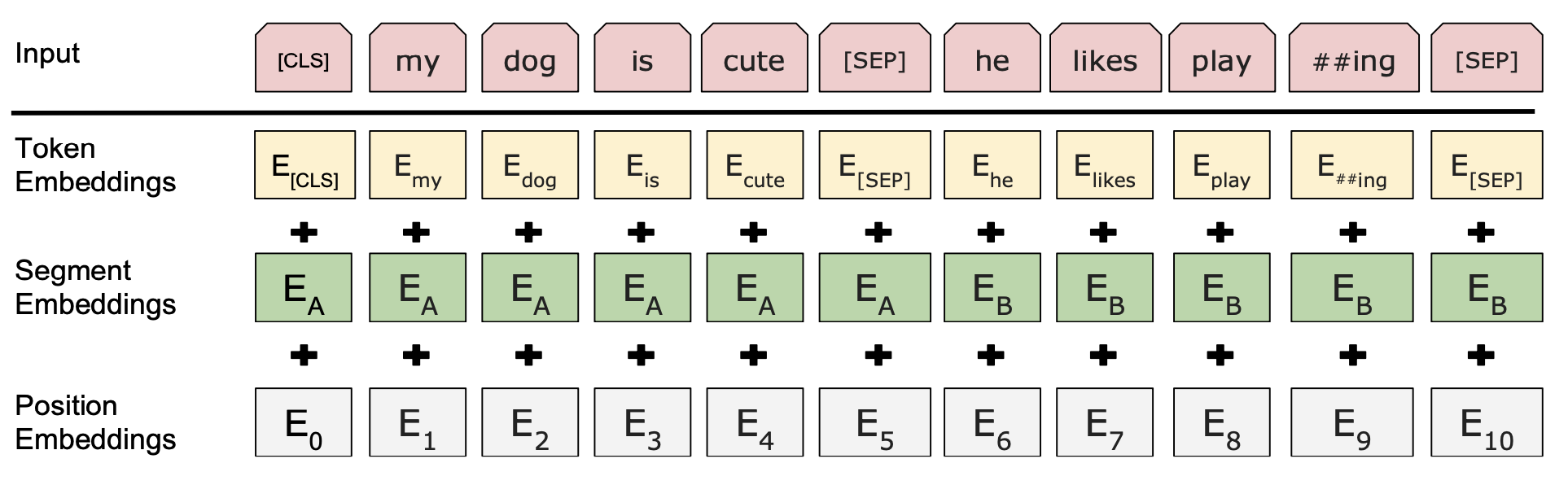
在模型组成上,BERT 相对于 Transformer Encoder 而言,encoder stack 的层数变为了 12 层;且在 Multi-Head Attention 子层中,BERT 的自注意力头的数目增加至 12 个,在保持原来的 的情况下,BERT 的 hidden state 维度也因此变为 ;相应的,BERT 的 FFN 的中间变量的维度也变为 ; 在 Embedding 阶段,Transformer 为了让输入序列拥有词序信息,因此令 input embedding 加上了一个 position encoding 矩阵使各个词语的词向量拥有位置编码信息;而这个 position encoding 是人为设定的,表现为与正弦、余弦函数取值有关;而 BERT 在 Embedding 阶段由三种 embedding 组成(如 Figure. 6 所示):Token Embedding, Segment Embedding 和 Position Embedding;其中,Token Embedding 用于将序列中的每个 token 转换为对应的词向量形式;Segment Embedding 用于区分特殊符号 [SEP] 前后的两个不同句子;Position 则根据各 token 的 index 序号,编码了不同 token 在序列中不同位置的信息。
# RoBERTa
RoBERTa 实际上是一个经过优化的 BERT 变体模型,作者团队在论文中提到,他们首先研究了对 BERT 的预训练过程进行修改会导致怎样的效果,之后根据与原 BERT 模型做效果对比,从多个方面提出了优化策略:
- 扩大了 BERT 的预训练语料库,特出表现为将预训练语料库从原来的 16G 大小扩大为 160G(增加了 CC-News, OpenWebText, Stories 语料库)
- 扩大了预训练的 mini-batch size,其依据为机器翻译任务中将 mini-batch size 大小提高,能够提升模型在该任务中的性能
- 将原本的 Mask LM 预训练子任务修改为能够让模型动态随机遮掩文本序列的词语
- 去除了 Next Sentence Prediction 预训练子任务,使得模型的一次输入内能够包含更多的句子
- 延长了模型的预训练时间,使得模型在获取文本特征的能力上得到提升
- 引入了 Byte-Pair Encoding,将 BERT 原本为 30K 的词典大小扩大为 60K,这使得 BERT 的输入序列出现未知文本符号 [unk] 的概率更少,减少它对模型性能的影响
# 效果对比
RoBERTa 的作者团队将所复现的 BERT 模型、XLNet 模型以及 RoBERTa 在 GLUE、SQuAD、RACE 等数据集上进行实验结果对比,如 Figure. 7 所示:
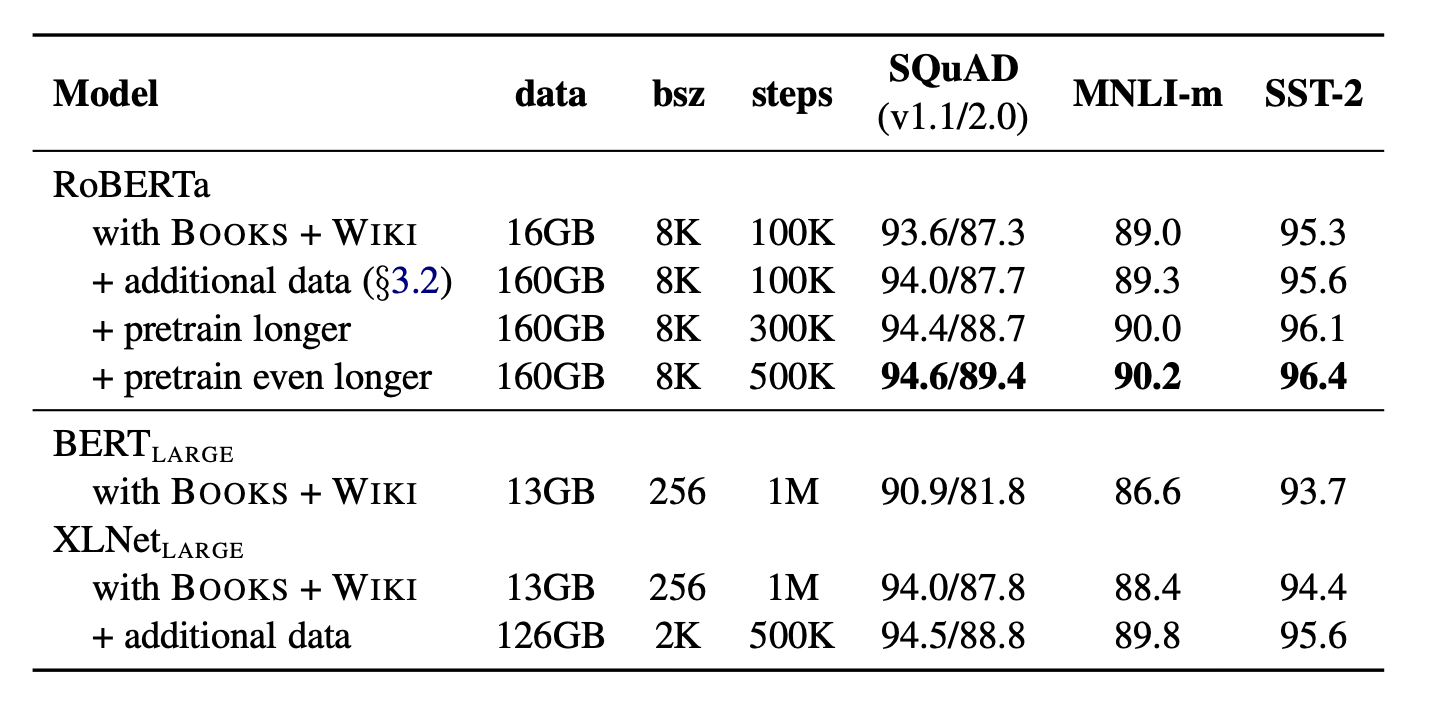
在实验中,RoBERTa 是基于 BERT_Large 实现的,而 XLNet 是在 BERT 之后提出的另一个预训练语言模型,其预训练的数据规模为 BERT 的 10 倍,所设置的 mini-batch size 为 BERT 的 8 倍,但预训练时长为 BERT 的一半;RoBERTa 所设置的 mini-batch size 为 BERT 的 10 倍,预训练时长分为 100K, 300K, 500K steps,最长为 BERT 的一半