
Prompt-based Learning Summarization
Prompt-based Learning has attracted widespread attention in the community, which is also considered as a new paradigm of natural language processing (NLP). Treating the specific downstream task as the language modeling task conducted in pre-training, prompt-based learning can alleviate the gap between pre-training and fine-tuning, and even induces pre-trained models' abilities of few-shot and zero-shot learning.
Thanks to the remarkable power of the "Pre-training + Fine-tuning" paradigm, most of the NLP tasks can be performed well by adapting Pre-trained Language Models (PLMs) to themselves. However, such effective strategy may induce definitely good performance on the condition that the following 3 "requirements" are prepared:
- The sufficiently large annotated dataset about the specific task
- Additional trainable parameters for the specific task
- Proper training objectives that benefit the fine-tuning
Actually, promising work based on "Pre-training + Fine-tuning" paradigm mostly adds appropraite neural network architectures for PLMs (e.g. feed forward network for task-specific classification and regression or graph neural network for encoding the syntactic information) and tunes both of those parameters simultaneously, which might lead to huge computational cost. Following the idea of fully supervised learning, only by introducing sufficient annotated data can prefectly tune PLMs and additional network architectures for the specific task. However, pursuing the annotated data is not always easy, which could be definitely difficult in low-resource situations like non-common langauges. Additionally, for those PLMs that contain billions of parameters, it is time-consuming and impracticle to fully tune the whole model. To address these issues, a new paradigm named "Prompt-based Learning" is proposed and utilized. The goals of "Prompt-based Learning" are adapting PLMs to the specific task with limited data and activate the abilities of PLMs, which might be learned from the Pre-training stage. Following them, the downstream tasks are reshaped as the objects of pre-training (e.g. Masked Language Modeling in BERT (Devlin et al., 2019) and Auto-regression Language Modeling in GPT (Radford et al., 2018) ) . Therefore, the most important factor of "Prompt-based Learning" is designing the proper methods to link the downstream tasks to the pre-training tasks.
# Preliminary
According to the consensus, the wave of research into Prompt-based Learning is ignited by GPT-3 (Brown et al., 2020), which can perform well in various NLP tasks while only receiving the descriptions of tasks. In this way, the task-relevant data is not provided but the model is expected to output something according to the description. Such an extremely difficult setting is called Zero-Shot Learning and it is an important application of Prompt-based Learning. Similarly, Few-Shot Learning focuses on building models with only few available samples (usually less than 100 or even 10 samples) while improving their performance in such low-resource situation.
# Entailment Model
An early strategy of Prompt-based Learning can be found in Zero-Shot Text Classification (Yin et al., 2019) . Though the term "prompt" is not proposed in this work, the core idea of Entailment Model formulates the input and output schemata in Zero-Shot Topic Detection, Emotion Detection and Situation Detection. Instead of converting these tasks to the Language Modeling task, prompts are designed to construct the hypotheses, which are related to the results of classification and inspired from the Natural Language Inference (NLI) task. As shown in Figure. 1, the interpretation is devised for interpreting the input text and it plays the role of the prompt template. Combining it with the schema of NLI, BERT trained on mainstream entailment datasets can perform well in three Zero-Shot Classification tasks mentioned above.
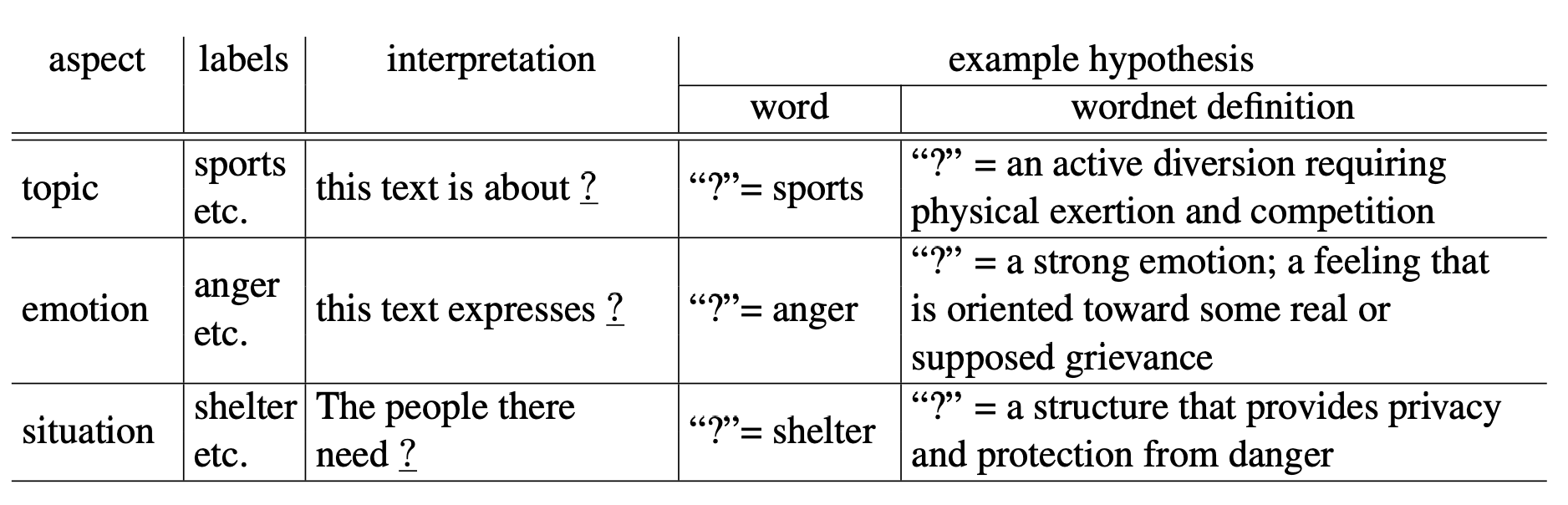
# Pattern Exploiting Training
One exciting Promp-based Learning approach is Pattern Exploiting Training (PET) proposed by Schick and Schütze (2021a) . Reformulating the input examples as cloze-style phrases, Masked Language Models can better understand what they receive and percept the tasks. A key factor to leverage the PET is pre-defining the cloze-style templates, which can be seen as prompts in Prompt-based Learning. Specifically, several templates are pre-defined in Figure. 2 for Topic Detection about the news. A typically application of PET is handling the Few-Shot Text Classification and Natural Langauge Inference: The limited annotated data is utilized to train the models through PET for generating the soft labels for unlabeled large-scale data, which can be treat as the supplement for Few-Shot Learning.

An obvious disadvantage of PET is the incompatibility between such pattern and multiple tokens prediction. To solve this problem, Schick and Schütze (2021b) extend the original implementation of PET, which is denoted as PET-extended here. As shown in Figure. 3, considering the word "terrible" will be tokenized into two individual tokens "terri" and "ble", the number of placeholder that represents the MASK token is determined by the maximum length of tokenization of the verbalizer (In Masked Language Modeling, the verbalizer is defined as the mapping from the prediction terms to labels). For example, if the maximum length is 2, then the prompt template "It was _" should contain 2 placeholders and change to "It was _ _" . At the inference stage, the procedure of PET-extended is different from its original version: the order of replacing the MASK tokens should be considered to optimize the multiple tokens prediction. Specifically, given the input sequence (with prompt template), the probabilities of different MASK tokens are compared and the larger one will be filled in the prompt firstly. As a result, the prediction of the remaining MASK tokens is affected by the prior predicted tokens.

# Variant
Though the power of Prompt-based Learning attracts numerous researchers and such schema is applied in different fields, the proper prompt templates and verbalizers are required to search in advance. According to Prompt-based Learning in Knowledge Probing (Petroni et al., 2019), different prompts induce different performance of the same PLM. The similar observation can be found in various NLP tasks such as Relation Extraction (Chen et al., 2022) and Sentiment Analysis (Mao et al., 2022). Additionally, designing proper prompts usually need domain knowledge and extensive trials. In order to capture the ideal prompts, many prominent researches have been conducted.
# Continuous Prompt
In most cases before, the prompt templates are devised as text sequences, which consist of discrete text tokens and carry rich semantics. Intuitively, such prompt templates can boost the PLMs' abilities of unstanding and perception; At least, they are explainable and comprehensible. However, for PLMs, it does not matter to receive prompts with or without semantics because they always regard them as sets of vectors (in other word, matrices) . Inspired by such characteristics, Zhong, Friedman and Chen (2021) propose a strategy called OptiPrompt that converts the tokens of prompt templates to continuous vectors. As illustrated in Figure. 4, unlike previous prompt templates, the templates of OptiPrompt are not natural language sequences and consist of some special non-word symbols.

For those continuous vectors, they are derived from the Word Embedding and optimized by the process of Back Propagation algorithm (Rumelhart et al., 1986). The initialization of them can summarized as two methods. One is randomly initialized (denoted as OptiPrompt in Figure. 4) and the other is manual initialization which utilizes the pre-trained embedding of selected words (denoted as OpptiPrompt (manual) in Figure. 4) . When applying OptiPrompt for specific downstream tasks, an idea to reduce the cost of computation is only tuning the continuous vectors. And tuning the full parameters of pre-trained language model will be helpful to pursue better performance.
# In-context Learning
Execpt for seeking the strategy that automatically search the templates and verbalizers, researchers have also exploited other directions to develop Prompt-based Learning. Gao, Fisch and Chen (2021) analyze the remarkable few-shot performance of GPT-3 and adopt the idea of incoporating demonstrations into the input sequences, which is denoted as "in-context learning" in (Brown et al., 2020) . Despite randomly selecting 32 examples from different classes and concatenating them with the input sequences, GPT-3's naive "in-context learning" is not available for most of the PLMs (the input sequences with such demonstrations are too long) and neglects the latent relationship between the input examples and others, which implies the selection of demonstrations should be elaborated. Therefore, as shown in Figure. 5(c), Gao, Fisch and Chen (2021) propose a refined strategy for dynamically and selectively constructing the demonstrations.

In order to leverage the relationship between each sample and improve the performance of prompt-based fine-tuning, this approach devise a sampling strategy for demonstration construction, which depends on the semantical similarity. Specifically, to the input example , the key to construct the demonstration is seaching all training instances and sorting them according to the similarity scores :
where means the classes exist in the training dataset ; is computing the cosine similarity and represents the embedding of input example or other training instance . In this approach, the implementation of is set as adopting the output of SBERT (Reimers and Gurevych, 2019).
# Automatic Template and Verbalizer
Besides incorporating demonstration in the input sequences, Gao, Fisch and Chen (2021) also propose the methods that automatically search for proper prompt templates and verbalizers. For the verbalizers, there are 3 steps to find the appropriate label words:
- Construct the pruned vocabulary of the original vocabulary by top vocabulary words based on their conditional likelihood using the initial PLM . Actually, the pruned vocabulary is also determined by the specific class in training dataset , which means different pruned vocabulary would be gotten ( is the input sequence with a fixed template ) :
- Select candidate label words over the pruned vocabulary according to the zero-shot accuracy in , which means verbalizers are required to perform the specific task in zero-shot setting and only candidate verbalizers will be chosen.
- Finally, the candidate verbalizers are utilized to fine-tune the PLM respectively and the best one will be found by comparing the performance in .
For the templates, an important factor should be considered firstly: The position of the prompt template. In fact, 3 popular solutions are regarding the prompt template as the prefix and suffix of the input sequence or placing it into the input sequence, shown in Figure. 6.

Although the formats of prompt templates can be confirmed, the number of tokens existing in the prompt template is difficult to design. However, following the ideas illustrated by Figure. 6, the generative T5 model (Raffel et al., 2020) is sutiable for handling this problem. Being similar to the generative tasks in T5's pre-training, the sentinel tokens play the roles of and in Figure 6. Therefore, it is simple to generate a diverse set of prompt templates by taking input sentences and label words from and inputting them to T5 models without having to specify a pre-defined number of tokens, which is shown in Figure. 7.

# Reference
[1] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[2] Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
[3] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
[4] Yin, W., Hay, J., & Roth, D. (2019). Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach. In 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019 (pp. 3914-3923). Association for Computational Linguistics.
[5] Schick, T., & Schütze, H. (2021, April). Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume (pp. 255-269).
[6] Schick, T., & Schütze, H. (2021, June). It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 2339-2352).
[7] Petroni, F., Rocktäschel, T., Riedel, S., Lewis, P., Bakhtin, A., Wu, Y., & Miller, A. (2019, November). Language Models as Knowledge Bases?. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (pp. 2463-2473).
[8] Chen, X., Zhang, N., Xie, X., Deng, S., Yao, Y., Tan, C., ... & Chen, H. (2022, April). Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. In Proceedings of the ACM Web conference 2022 (pp. 2778-2788).
[9] Mao, R., Liu, Q., He, K., Li, W., & Cambria, E. (2022). The biases of pre-trained language models: An empirical study on prompt-based sentiment analysis and emotion detection. IEEE Transactions on Affective Computing.
[10] Zhong, Z., Friedman, D., & Chen, D. (2021, June). Factual Probing Is [MASK]: Learning vs. Learning to Recall. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 5017-5033).
[11] Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. nature, 323(6088), 533-536.
[12] Gao, T., Fisch, A., & Chen, D. (2021). Making pre-trained language models better few-shot learners. In Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL-IJCNLP 2021 (pp. 3816-3830). Association for Computational Linguistics.
[13] Reimers, N., & Gurevych, I. (2019, November). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (pp. 3982-3992).
[14] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1), 5485-5551.