
Reading Note:Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training
From: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
URL: https://aclanthology.org/2021.emnlp-main.22/
Authors: Zhengyan Li, Yicheng Zou, Chong Zhang, Qi Zhang, and Zhongyu Wei.
The paper that I currently read called Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training. Obviously, this paper focuses on Implicit Sentiment and Contrastive Learning, which attracted me to figure out the meaning of Implict Sentiment and its analysis.
So what is implicit sentiment? Implicit sentiment indicates sentiment expressions that don't contain obvious polarity markers. Specifically, implicit sentiment in Aspect-based Sentiment Analysis represents that the target sentence doesn't contain Opinion Term. Despite implicit sentiment expressions are "incomplete", they still convey clear human-aware sentiment polarity in context(Russo et al., 2015).

Here is a review which contains explicit and implicit sentiment. And two aspects from it are signed by red(explicit) and brown(implicit). It's obvious that no opinion terms are mentioned for the aspect "service"
Recently, few researchers focus on the implicit sentiment expressions in Aspect-based Sentiment Analysis, so I tried to learn how to handle such situation by reading this paper.
# Motivation
According to the statistics on two bechmark dataset of Aspect-based Sentiment Analysis, Li et al. found that implicit sentiment expressions widely exist among the Restaurant and Laptop dataset. Table. 1 illustrates the proportion of implicit sentiment expressions(ISE) in such 2 bechmark datasets and 3 external datasets(MAMS, YELP, Amazon). The result shows that we must face with ISE and correctly handle them in actual research.

Table.1: The last column of the table shows the proportion of implicit sentiment expressions in datasets respectively, which indicates the importance of handling implicit sentiment.
What's more, although many effective approaches based on different areas, for example Graph Neural Network(GNN) and Pre-trained Language Model, had been proposed, they doesn't performs well when facing with ISE. That's another reason why Li et al. would like to seek a new approach to solve this problem.
# Approach
Even though there are many samples of ISE in Restaurant and Laptop datasets , it is insufficient to train a strong enough model to distinguish explict and implict sentiment expressions. So Li et al. retrieved an external corpus for pre-training. However, the external corpus is based on Sentiment Analysis of reviews, not aspects. In the pre-trainning and find-tuning situations, Li et al. propose Supervised ContrAstive Pre-Training(SCAPT) and Aspect-Aware Fine-tuning respectively.
# Supervised Contrastive Pre-training
In this pre-training approache, the whole process is divided into three parts: Supervised Contrastive Learning, Review Reconstruction, Masked Aspect Prediction. The pre-training scheme is built on Transformer Encoder and the overall of the pre-training architecture is illustrated by Fig. 1.
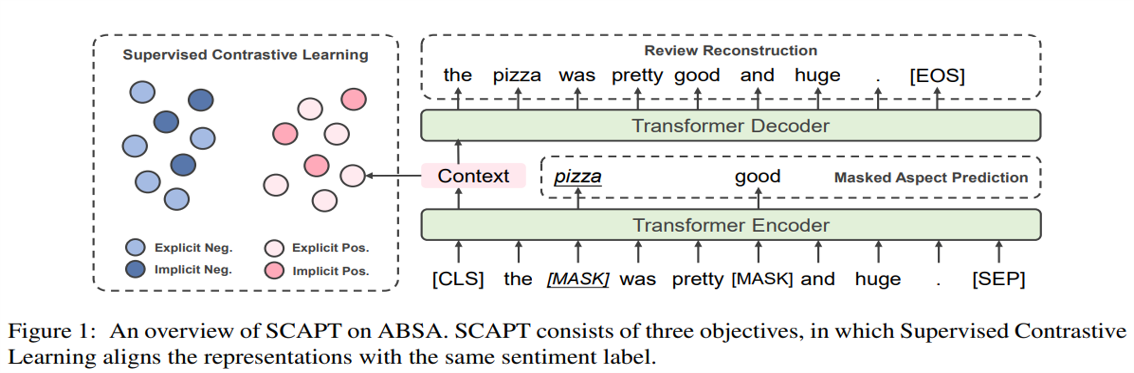
Let's analyse the detail of three component resepctively!
# Supervised Contrastive Learning
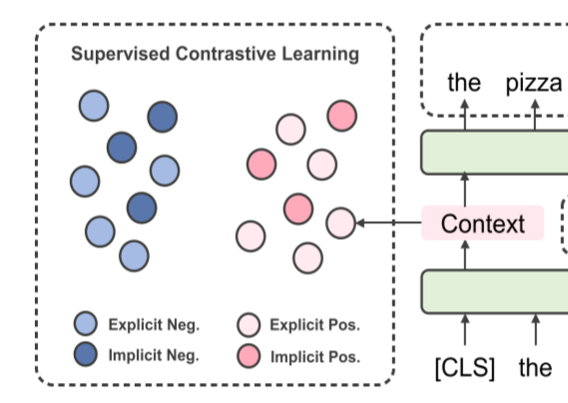
Following the feature of Supervised Contrastive Learning, the sentences are denoted with labels correspondingly. Here we mark the pair of sentence and label at a batch with "()", where is the sentence and is its label. Inspired by Devlin et al., the input of transformer is denoted by and the output vector of [CLS] token encodes the sentence representation .
To align the representation of explicit sentiment and implicit sentiment expressions with the same polarity, Supervised Contrastive Learning encourages the model to capture the entailed sentiment orientation in context and incorporate it in sentiment representation. In other words, the purpose of Supervised Contrastive Learning is chaging the sentence representation() so it can contain the information of sentiment ( could be seen as a trainable sentiment perceptron for sentences).
But how to change and optimize the sentence representation? Li et al. utilize the sentences from the external corpus which were signed by 4 labels(Explicit Neg, Explicit Pos, Implicit Neg and Implicit Pos) and construct the contrast. The supervised contrastive loss on the batch is defined as:
For the first formula, are the reviews which belongs to the same category of and represents the other reviews in the batch . indicates the likelihood that is most similar to and is the temperature of softmax. The similarity function() used is the dot product. And for the second formula, supervised contrastive loss is calculated for every sentence among the batch where is the number of samples in the same category in .
Because of supervised contrastive loss, the model can make full use of the retrieved corpus and mining the inherent sentiment perception for the sentence representations.
# Review Reconstruction

Motivated by the success of denoising auto-encoder in pre-training models(Lewis et al., 2020), this paper utilizes the review reconstruction to enhance the sentence representation on context semantic modeling. An important reason why utilizing review reconstruction is that the essential semantic information is not completely preserved in the sentence representations after the procedure of supervised contrastive learning. Thus, this approach must additionally employ review reconstruction to capture comprehensive context information in sentence representations. The main ideal of this componment is decoding the the sentence representation by the decoder and check whether the result of decoding is as same as the sentence . The procedure could be simplified as:
is the recovered sentence. And the original text of the sentence is the reference of review reconstruction objective, so the loss function is:
# Masked Aspect Prediction

In this componment, model learn to predict the masked aspects from a corrupted version The masking strategy of input reviews consists of following two steps: Aspect span masking and Random masking. To aspect span masking, the tokens of aspect spans in each review are replaced with [MASK] with 80% probability, or replaced with a random token with 10% probability, otherwise kept unchanged.
To random masking, if the proportion of masked tokens is less than 15% after aspect span masking, the model will randomly mask extra tokens from the rest ones to reach the proportion.
For each masked token at k-th position, its contextualized hidden representation is denoted as . And it is the input of the softmax layer to predict the original text:
In this equation, is a trainable parameter matrix and indicates the probability of the original text of the word which is in the k-th position. The loss function is:
According to Li et al., masked aspect prediction focuses more on modeling aspect related context information in aspect-based relation and it benefits the following fine-tuning scheme.
# Joint Training
Because the approach of pre-training proposed in this paper is a joint approach that focuses on multi-tasks simultaneously, the loss functions of each component should be jointly concatenated. However, For the overall pre-training loss on batch , the review reconstruction loss and masked aspect prediction loss are counted on each example, there are two hyperparameters and to balance the whole equation:
# Aspect-Aware Fine-tuning
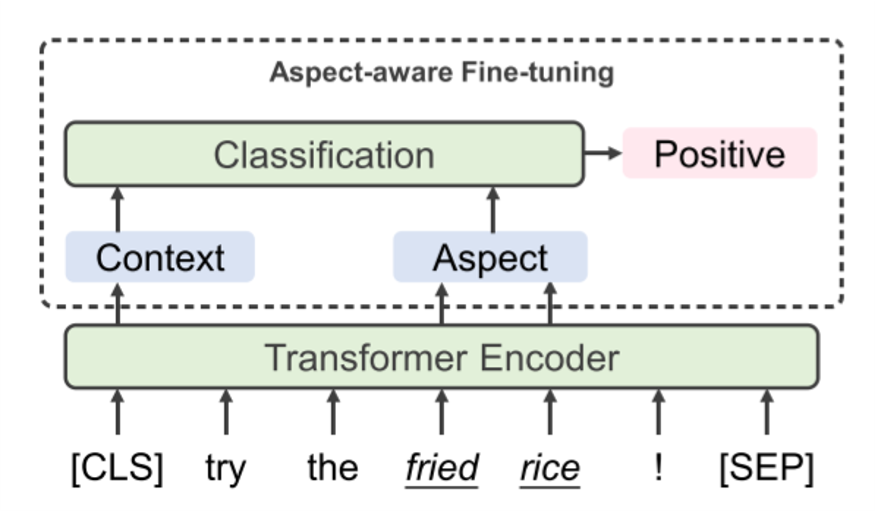
After the procedure of pre-training, the model could capture the implicit sentiment information, but in order to accurately classify the sentiment polarities of the aspects, it is necessary to fine-tune the component that coordinates with the classification.
Let's assume an aspect term occurring in the sentence , then we denote it to .Inspired by the rearch(Ethayarajh, 2019) on pre-trained contextualized word representation which has demonstrated that such representation can capture context information related to the word, this paper chooses to extract aspect-based representation by collecting the final hidden states from the encoder that correspond to . One more thing that we should consider is the aspect term() may not consist of only 1 token. Thus, the representation may consist of 2 or more vectors. Then, it's important for the model to average the hidden state for all indexes of to acquire aspect-based representation. Let's denote the token index to , then for all , the aspect-based representation is:
Finally, in order to let the model build the perception of both word-occurrence-related explicit sentiment and semantic-related implicit sentiment, for each sentence , Li et al. concatenates the sentiment representation of and the aspect-based representation of the aspect term from . In the end, the predicition of sentiment polarity of in is:
And the cross-entropy loss for prediction task is:
where means the ABSA dataset.
# Experiment

Table.2: This is the statistics on three bechmark datasets of ABSA(Resturant, Laptop and MAMS) and two external corpus for SCAPT. We can easily notice that the implicit sentiment wildly exists at Resturant and Laptop dataset.
After viewing Table.2, we can know why the model should be able to understand the implicit sentiment. And in order to achieve this goal, what a strive that Li et al. search such two large dataset(YELP and Amazon). What's more, to align the reviews from three bechmark dataset, Li et al. only picked the reviews scored by users and made sure the scores of them must be 1 or 5(as negative and positive samples).
And here is the result of the experiment. Li et al. chooses transformer encoder and BERT respectively. In the last 3 rows, CEPT means replacing the supervised contrastive learning loss with cross-entropy in SCAPT.
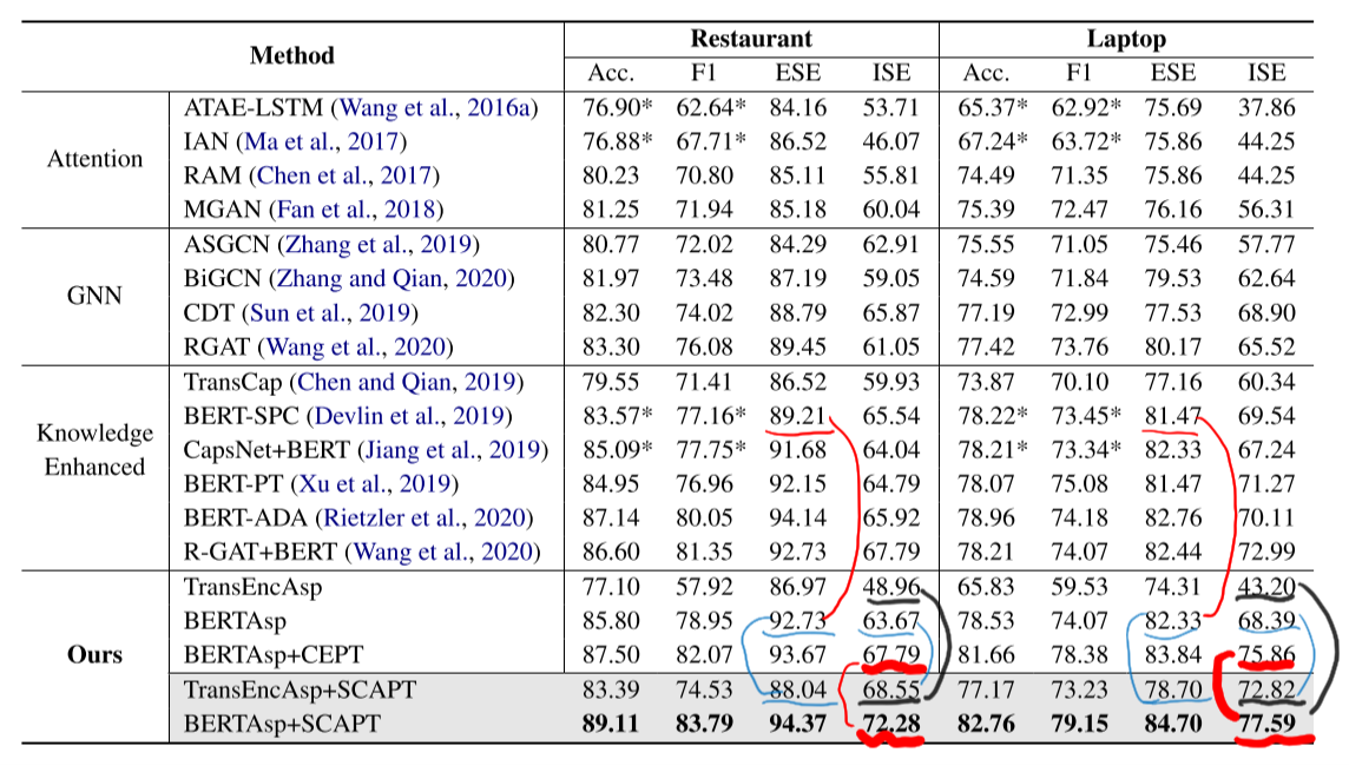
We can find that the ability of BERT is powerful with the aspect-based fine-tuning and the supervised contrastive learning, comparing with the baseline models which consists of BERT. And the results of BERT-based models are usually greater than the results of transformer-based models. In my opinion, that's why pre-training language models are always used for NLP tasks now.
After reading this paper, I would like to conclude:
- It is feasible and helpful to import the ideal of contrastive learning to ABSA.
- The contextualized word representation can obtain the semantic information of the sentence, so it's important to augment the context feature of aspects.
# Reference
[1] Irene Russo, Tommaso Caselli, and Carlo Strapparava. 2015. SemEval-2015 task 9: CLIPEval implicit polarity of events. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), pages 443–450, Denver, Colorado. Association for Computational Linguistics.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
[3] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
[4] Kawin Ethayarajh. 2019. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 55–65, Hong Kong, China. Association for Computational Linguistics.